Warum 100% Indexierung Deiner Inhalte ein SEO-Mythos ist
Es ist ein SEO-Schmerz, der immer schlimmer wird: Mit zunehmender Anzahl an verfügbaren Seiten im Web werden immer weniger Seiten indexiert. Selbst wichtige Seiten werden mittlerweile nicht mehr so schnell indexiert wie vor einigen Jahren. Das ist vielen SEOs ein Dorn im Auge. Das liegt u. A. schlichtweg daran, dass Google insgesamt weniger URLs crawlt als früher. Aber ist es überhaupt möglich, alle Inhalte indexiert zu bekommen? Und ist es sinnvoll, alle Inhalte einer Website zu indexieren? Was sind potenzielle Probleme, die einer Indexierung im Weg stehen? Wir schauen uns das nachfolgend näher an.

Inhalt
- Ein Blick zurück: Wie sich das Crawling und die Indexierung im Laufe der Zeit verändert haben
- Googles Crawling-Budget verstehen
- Wie steuere ich am besten das Crawling und Indexieren meiner Inhalte?
- Wie kann ich mein Crawling-Budget erhöhen?
- Ist es sinnvoll, alle meine Website-Inhalte zu indexieren?
- Welche Inhalte sollen indexiert werden?
- Welche Inhalte müssen nicht indexiert werden?
- Wie merke ich, ob ich Indexierungsprobleme habe?
- Warum Seiten nicht indexiert werden
- Tipps zur Verbesserung der Indexierung von Inhalten
- Fazit
Ein Blick zurück: Wie sich das Crawling und die Indexierung im Laufe der Zeit verändert haben
Früher betrafen Crawling- und Indexierungsprobleme primär nur wirklich große Websites oder Seiten, die sich aber durch viele Inhaltsänderungen charakterisierten und somit ebenfalls häufig von Google „besucht“ werden sollten. Nun hat sich das Bild jedoch dahingehend geändert, dass auch viele kleinere Websites vor Herausforderungen bezüglich des Crawlings und Indexierens ihrer Inhalte stehen. Mit zunehmender Anzahl an URLs im Web, muss auch Google priorisieren, welche Seite es wert sind, gecrawlt und indexiert zu werden.
Die Indexierung von Inhalten bei Google hat sich im Laufe der Jahre erheblich verändert, da die Suchmaschine ständig an ihren Algorithmen und Technologien feilt, um relevantere Suchergebnisse für die Benutzer bereitzustellen. Nachfolgend haben wir eine grobe Übersicht über die Entwicklung der Indexierung bei Google in der Vergangenheit als auch in der Gegenwart zusammengestellt:
Vor einigen Jahren:
- Statisches Crawling: Früher hat Google hauptsächlich auf statisches Crawling gesetzt. Das bedeutet, dass die Suchmaschine Webseiten periodisch besucht hat, um nach neuen Inhalten zu suchen. Dies geschah in relativ langen Intervallen.
- Keywords: Die Indexierung basierte hauptsächlich auf Keywords. Google hat die Keywords in den Inhalten erkannt und diese als Grundlage für die Anzeige von Suchergebnissen verwendet. Dies führte zu Keyword Stuffing seitens der Websitebetreiber und somit weniger relevanten Suchergebnissen.
- Manuelle Indexierung: Webseitbetreiber hatten die Möglichkeit, ihre Websites manuell bei Google einzureichen. Bis noch vor einigen Jahren konnten Webmaster neben einer bestimmten URL noch direkt verlinkte URLs zum Neu-Crawl „aktivieren“. URLs wurden anschließend rasch in den Index aufgenommen. Heute ist die URL-Abfrage nur mehr auf Einzelbasis möglich und auch der Prozess der Indexierung zögert sich teils länger hinaus. Dies ist darin begründet, dass das Abrufen über die GSC heutzutage ein schwächeres Signal darstellt als früher. Hintergrund: Hierbei wurde das „Request Indexing Tool“ zu häufig für die Indexierung von Inhalten geringerer Qualität eingesetzt, weshalb Google hier vorsichtiger geworden ist.
Heute:
- Echtzeit-Crawling: Google verwendet jetzt einen Echtzeit-Crawling-Ansatz. Das bedeutet, dass die Suchmaschine Webseiten häufiger und schneller besucht, um neue Inhalte zu entdecken. Dies ermöglicht eine schnellere Indexierung von neuen Informationen.
- Ranking-Algorithmen: Google hat seine Algorithmen erheblich verbessert und verwendet Hunderte von Faktoren, um die Relevanz von Suchergebnissen zu bewerten. Keywords sind immer noch wichtig, aber sie sind nur ein Teil des Gesamtbildes.
- Mobile First: Google hat sich auf die mobile Indexierung verlagert, was bedeutet, dass die mobile Version einer Website für die Indexierung und das Ranking entscheidend ist.
- User Experience: Google bewertet auch die Nutzererfahrung auf Websites, einschließlich der Ladezeit, der Mobilfreundlichkeit und der Sicherheit (HTTPS). Diese Faktoren beeinflussen das Ranking in den Suchergebnissen.
- Featured Snippets und Rich Results: Google zeigt häufig Featured Snippets, Rich Results und Knowledge Panels in den Suchergebnissen an, um den Benutzern direkt Antworten auf ihre Fragen zu liefern.
- Voice Search und AI: Die Verbreitung von sprachgesteuerten Suchanfragen und die Verwendung von Künstlicher Intelligenz (KI) beeinflussen die Art und Weise, wie Google Inhalte indexiert und bereitstellt.
Googles Crawling-Budget verstehen
Dem Googlebot steht nur eine begrenzte Zeit je Website zum Crawlen zur Verfügung. Dieses sog. „Crawling-Budget“ bezeichnet die aufgewendete Zeit und Ressourcen, welche Suchmaschinen wie Google für das Durchforsten („Crawlen“) einer Website benötigen.
Laut dem „Handbuch für Websiteinhaber zur Verwaltung des Crawling-Budgets“ gibt es zwei Hauptfaktoren, die das Crawling-Budget beeinflussen:
- Crawling-Kapazitätslimit: Dies gibt an, wie viele Verbindungen maximal gleichzeitig für das Website-Crawling verwendet werden dürfen und mit welchen Zeitintervallen zwischen den Abrufen.Wenn Deine Website bspw. schneller reagiert und kürzere Antwortzeiten aufweist, wirkt sich dies positiv auf das Limit aus. Geschieht das Gegenteil und die Website lädt langsamer, so crawlt der Googlebot wieder weniger. Darüber hinaus kannst Du als Websiteinhaber auch die Crawling-Frequenz Deiner Website für Google einschränken (nur dann anzudenken, wenn durch die vielen Google-Zugriffe Probleme bei Deiner Serverlast auftreten). Ein dritter Faktor sind Crawling-Limits seitens Google, welche ihre Ressourcen bestmöglich einsetzen müssen.
- Crawling-Bedarf: dieser wird durch die Größe, Seitenqualität, Aktualisierungshäufigkeit und Relevanz einer Website im Verhältnis zu anderen Websites bestimmt.Dabei spielt u. A. die Beliebtheit von URLs bzw. Inhalten eine Rolle, denn Google ist bestrebt, beliebtere URLs häufiger zu crawlen und aktuell zu halten. Auch die Aktualität Deiner Inhalte spielt mit rein, denn hier ist Google auch bemüht, Änderungen an Inhaltsseiten schnell zu erkennen und zu indexieren. Zudem solltest Du die zu crawlenden Seiten für Google gut steuern, sodass die Suchmaschine hier möglichst nicht auf sich alleine gestellt ist: Denn erhält Google von Dir keinerlei Info über was zu crawlen ist, bahnt sich Google den Weg durch Deine Website selbst und stößt womöglich auf index-irrelevante URLs wie Duplikate, weitergeleitete oder nicht mehr vorhandene Links. Folglich kann das in den Augen von Google als Zeitverschwendung beim Crawling Deiner Website interpretiert werden.
Nach dem Crawlen, der Evaluierung und Bewertung der Seiten, wird erst entschieden, ob die Inhalte auch indexiert werden. Die Menge der Crawling-Ressourcen einer Website bestimmt Google durch die Beliebtheit, den Wert für den Nutzer, die Einzigartigkeit und der Bereitstellungskapazität.
Wie steuere ich am besten das Crawling und Indexieren meiner Inhalte?
- txt: Hiermit wird bereits das Crawling einer URL bzw. eines Verzeichnisses unterbunden. Somit sieht Google auch nicht etwaige Meta-Robots-Angaben auf der Zielseite. Dies ist bei großen Websites bzw. Websites, die aus verschiedenen Gründen massenhaft unnötige URLs generieren, sinnvoll – sprich bei sehr oft gecrawlten, aber jedoch überflüssigen Verzeichnissen bzw. Mustern wie z. B. bei Filter- und Sortier-URLs. Somit lässt sich bereits das Crawling-Budget optimieren. Wenn Du diese Methode einsetzen möchtest: Prüfe mit dem robots.txt-Tester im Vorfeld, dass keine ungewollten Sperren erfolgen. Besondere Vorsicht gilt es bei zu großzügigen Wildcard-Sperren (z. B. Wortbestandteile wie „test“) walten zu lassen und bei URLs, die noch indexiert sind. Als Folge können Seiten nicht mehr gecrawlt werden, die aber ggf. doch von Relevanz sind. Zudem kann eine Sperrung von bereits indexierten Seiten zu einer „Explosion“ genau jener Seiten im Index mit der Info in den SERPs, dass „für diese Seite keine Informationen verfügbar sind“, führen.So ist bei zalando.de bspw. die Robots.txt-Datei aufgebaut:
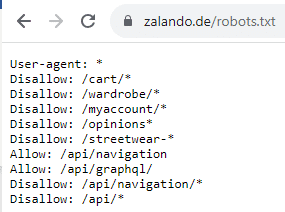
Aufbau der Robots.txt-Datei am Beispiel von zalando.de
- Canonical-Tag: Diese Angabe im Quelltext oder HTTP-Header Deiner Website bietet sich bei der Behebung von Website-Duplikaten an. Aber Achtung: diese werden unserer Erfahrung nach von Google nur akzeptiert, wenn der Inhalt des Duplikats auch wirklich nahezu identisch ist. Weichen die beiden Seiten inhaltlich zu stark ab, kann Google die Canonical-Angabe auch ignorieren. Code-Beispiel:
<link rel=“canonical“ href=“https://www.zalando.de/kinderschuhe/„>
- Noindex-Tag: Ausschluss einer URL oder eines gesamten Pfads über den Noindex-Tag. Hierbei crawlt Google die betroffenen Bereiche, indexiert diese nur nicht. Der Code lautet:<meta name=“robots“ content=“noindex“>
Wie kann ich mein Crawling-Budget erhöhen?
Hierbei stehen Dir diese Möglichkeiten zur Verfügung:
- die Erhöhung der Bereitstellungskapazität für das Crawling, sprich Google kann Deine Website problemlos crawlen und es führt zu keiner Überlastung Deines Servers durch die Googlebot-Anfragen. Stelle sicher, dass Deine Website bzw. Dein Web-Server Anfragen schnell verarbeiten kann und Google keine massigen Ressourcen laden muss, die die Suchmaschine ggf. dazu anhalten könnten, die Crawl-Frequenz als auch die Tiefe (Anzahl) zu minimieren. Stichwort: Pagespeed 😉 Ein paar Quick-Tipps, wie ihr die Ladezeit überprüfen und sofort verbessern könnt, gibt Dir meine Kollegin Nora. Behalte zudem Fehlerseiten wie jene mit Status Code 404 oder 500 im Blick und versuche diese stets minimal zu halten: Eine Übersicht erhältst Du über die Crawling-Statistik der Google Search Console, dem Screaming Frog oder die Log-Files, die Du mit dem Screaming Frog Logfile Analyzer auswerten kannst.
Nachfolgend ein Beispiel aus einer Crawling-Statistik der Google Search Console mit vielen URLs, die nicht gefunden werden konnten und Seiten, die temporär nicht erreichbar waren. Hier gilt es anzusetzen: Gründe finden und Probleme ausmerzen:

Blick in die Aufschlüsselung der Crawling-Anfragen nach Antwort (Crawling-Statistik in der GSC)
- die Steigerung der nutzenstiftenden Inhalte Deiner Website für Deine Zielgruppe, sprich: Achte noch mehr darauf, dass Deine Inhalte wirklichen zusätzlichen Mehrwert gegenüber bieten und sich von Deiner Konkurrenz abheben.
- Google liebt es beliebte Inhalte zu crawlen: Wenn Deine Website oder eine URL noch über sehr wenige eingehende Links verfügt, so versuche Deinen Inhalt in die Welt hinauszutragen und Backlinks zu erhalten. Nutze dazu auch gern Deinen Social Media-Auftritt, um Deine Inhalte zu platzieren.
Ist es sinnvoll, alle meine Website-Inhalte zu indexieren?
Es mag theoretisch technisch möglich sein, alle Website-Inhalte zu indexieren – speziell bei kleineren Websites und angenommen alle Deine URLs sind auf „index“ gestellt und besitzen weder ein „noindex“-Tag noch einen Canonical Link auf eine andere Seite oder sind via robots.txt gesperrt – aber praktisch wird dies kaum mehr zu erreichen sein.
Vielmehr ist es wichtig, unter Betrachtung der zunehmenden Anzahl an URLs im Web, dass Du nur mehr die für Deinen SEO-Erfolg relevanten URLs für den Google Index freigibst. Je nach Branche und Website-Typ gibt es auch Bereiche, die Google gar nicht erst crawlen soll und mittels robots.txt-Datei ausgeschlossen werden können. Diese Ausschlüsse sind technische Rahmenbedingungen, die SEOs in der Hand haben und direkt steuern können.
Nach dem ersten „Aussieben“ von nicht index-relevanten Inhalten und somit „vorpriorisieren“ für Google, sollten dann nur mehr jene für Dich relevanten Seiten gecrawlt und indexiert werden. Hierbei kommt ein Thema besonders zum Tragen: Nutzenversprechen von Inhalten, sprich welchen Sinn und Zweck verfolgen die Seiten und wie qualitativ hochwertig ist der Inhalt der Zielseite. Webmaster können wertvolle Inhalte bereitstellen, aber dennoch entscheidet Google, ob diese auch indexiert werden. Wenn die Inhalte nicht den Vorstellungen einer nutzenversprechenden Zielseite entsprechen, werden diese als Seiten mit geringer Seitenqualität eingestuft. Da ist es egal, wie optisch ansprechend Inhalte sind: wenn Deine Zielseiten keinen bestimmten Zweck und Mehrwert erfüllen, kann Google von einer Indexierung absehen.
In diesem Zusammenhang ist es wichtig, sich im Vorfeld mit Googles Qualitätsrichtlinien auseinanderzusetzen und diese zu beachten – ein Anforderungskatalog, welcher aufzeigt, ob eine Inhaltsseite die notwendige Qualität aufweist, um indexiert zu werden.
Welche Inhalte sollen indexiert werden?
Jene URLs, die für Traffic auf Deine Website sorgen und Umsätze bzw. Conversions generieren. Um dies zu beurteilen, bietet sich u. A. Google Analytics an. Eine wichtige Grundlage für (organischen) Traffic als auch folglich Umsätze ist, ob Deine Seite noch „in the making“ oder bereits online ist, die Keyword-Recherche. Diese deckt die aktuellen sowie auch noch ungenutzten Potenziale Deiner Website auf. Nimm dazu auch direkt die aktuelle Position mit auf – entweder über diverse Keyword-Monitoring Tools (wie SISTRIX oder AccuRanker) oder die durchschnittliche Position der letzten 7 Tage aus der Google Search Console für das jeweilige Keyword. Du brauchst Unterstützung? Melde Dich unverbindlich bei uns. Wichtig ist, den Fokus bei der Textierung auf für Deine Nutzer:innen relevante Inhalte zu legen und deren Erwartungen zu kennen und zu erfüllen.
Tipp: Schaue regelmäßig in den Leistungsbericht Deiner Google Search Console Property. Dort siehst Du ganz genau ein, über welche Suchbegriffe die Nutzer auf Deine Website kommen. Wie ist der Verlauf? Nimm Feinjustierungen vor, wenn es noch Luft nach oben gibt und arbeite stets an Deinem Content, um den Nutzerintentionen gerecht zu bleiben. Und behalte stets im Auge, dass Deine wichtigen URLs auch bei Google indexiert bleiben.
Welche Inhalte müssen nicht indexiert werden?
Es gibt zahlreiche Fälle, wo wir von einer Indexierung von Inhalten absehen würden. Nachfolgend einige Beispiele:
- Interne Bereiche, die erst nach einem Login erreichbar sind, wie z. B. Mitarbeiter-Bereiche oder Nutzeraccounts in Shops.
- Weitere nutzerspezifische URLs, die nur für bestimmte Personen oder Personengruppen und nicht für die Öffentlichkeit bestimmt sind: Zum Beispiel Links zum Download von Bildern nach Fotoshootings oder Inhalte wie E-Books, die erst nach Eintrag im Mail-Verteiler o. Ä. freigeschaltet werden.
- Danke- und Kaufbestätigungs-Seiten nach Bestellungen oder Anmeldungen.
- Doppelt vorhandene Inhalte: Gleiche Inhalte, die über mehrere URLs aufrufbar sind, sollten idealerweise mit einem 301-Redirect auf eine definierte Haupt-Version gelöst werden. Somit wird das Crawling-Budget eingespart und Du verschlankst Deine Seite. Wenn eine Weiterleitung nicht möglich sein sollte, empfiehlt sich der Einsatz von Canonical-URLs auf die Hauptversion, wie z. B. bei Druckversionen.
- Seiten mit Paginierung. Gerade in großen Onlineshops ist es nahezu unvermeidlich, die vielen Produkte auf mehrere Seiten aufzuteilen, um die Ladezeit nicht negativ zu beeinflussen. Somit kann Google die Produkte finden und crawlen. Die Aufnahme dieser Paginierungsseiten in den Index bietet jedoch häufig keinen Mehrwert und sollte daher mit einem „Noindex-Tag“ ausgeschlossen werden. Aber Vorsicht: Stelle sicher, dass Produkte bzw. Beiträge nicht nur über paginierte Seiten erreichbar sind. Denn wenn eine (paginierte) URL lange Zeit auf noindex steht, so wird Google sie irgendwann weniger häufig oder gar nicht mehr crawlen. Auf ihr verlinkte Seiten haben dann faktisch keine “internen” Links mehr.
- Seiten mit Filterung und Sortierung: Je nachdem wie viele Filter- und Sortiermöglichkeiten bestehen, kann eine Freigabe zur Indexierung den Index mit ziemlich vielen irrelevanten URLs fluten. Auch hier bietet es sich an, mit einem „Noindex-Tag“ zu arbeiten oder diese gänzlich via robots.txt zu sperren. Sollte Suchvolumen und Nutzerinteresse für bestimmte Filtermöglichkeiten bestehen, so empfehlen wir dafür eigene, optimierte Kategorieseiten mit statischen URLs zu erstellen. Wenn es technisch möglich ist, auch bei Filter-URLs individuelle Seitenoptimierungen an Überschriften und Meta-Daten vorzunehmen, kann alternativ auch die Filter-URL indexiert bleiben (wichtig: keine Sperre über robots.txt-Datei).
- Seiten oder Domains, die sich noch in der Entwicklung bzw. Testphase befinden. Klassisches Beispiel: der Relaunch einer Website wird vorgenommen. Auch hier sollte die entsprechende Domain nicht indexiert werden. Hier am besten mit „noindex, nofollow“ und einem Passwortschutz arbeiten.
- Veraltete, archivierte Inhalte sowie für den User gänzlich irrelevante Inhalte. Crawle Deine Webseite mit dem bspw. dem Screaming Frog und untersuche, welche URLs es gibt. Sind darunter etwaige vom CMS automatisch generierte URLs, die keinen Mehrwert bieten und somit auch nicht indexiert werden sollten? Gibt es noch weitere „URL-Leichen“, die eliminiert werden sollten?
Wie merke ich, ob ich Indexierungsprobleme habe?
Als kleines Beispiel aus dem Jahr 2021 von Gary Illyes: hier wurde ein Fall aufgezeigt, wo eine Seite immer mal aus dem Google Index verschwindet, aber nach dem erneuten Abruf über die GSC wieder in der Google-Suche erscheint. Antwort: Die Seite fällt gelegentlich aus dem Index, da die Qualität der Zielseite aus Googles Sicht nicht ausreichend genug ist, die Seite langfristig zu indexieren:
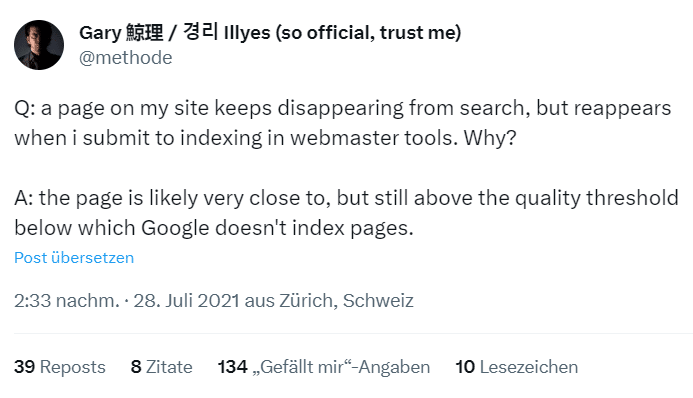
Screenshot aus „X“, vorher „Twitter“ und dem Profil von Gary Illes zu einer Nutzerfrage
Hier hilft also nur: Hinsetzen und nacharbeiten.
Wenn es Dir nicht bei bestimmten überwachten URLs wie am Beispiel oben auffällt, dass diese nicht mehr indexiert sind, hilft Dir für eine generelle Übersicht der Abdeckungsbericht in der Google Search Console (GSC). Dort kannst Du nachschauen, wie das Verhältnis von indexierten zu nicht indexierten Seiten ausfällt. Steigt die Anzahl an nicht indexierten Seiten an, so sollten diese URLs näher inspiziert und geprüft werden: Handelt es sich hierbei um wichtige Traffic- und Umsatzbringende URLs, die somit indexiert sein müssen oder eher um irrelevante URLs, die zurecht nicht indexiert sind? Dies findest Du in diesem Bericht heraus:

Blick in einen Beispiel-Abdeckungsbericht, wo die nicht indexierten Seiten steigen
Wenn für Dich wertvolle URLs aus Index fallen, gilt es als Nächstes zu verstehen, warum dies so ist.
Tipp: Du kannst mit dem URL-Prüftool in der Google Search Console schnell herausfinden, ob Deine URL indexiert und wenn nein, warum nicht.
Warum Seiten nicht indexiert werden
Es gibt eine Vielzahl von Gründen, warum URLs nicht indexiert werden, wie zum Beispiel:
- Seite ist neu und Google hat noch keine „Info“ über die neue Seite erhalten (über Backlinks, interne Links, Sitemap etc.) und konnte diese somit noch nicht crawlen und indexieren.
- Seite ist für die Indexierung nicht zugelassen (wie z. B. Sperrung über robots.txt-Datei, Seite besitzt noindex-Tag oder Canonical-Link auf eine andere Seite).
- Seite ist aus diversen Gründen nicht mehr aufrufbar (wie z. B. gibt Status Code 404 oder 500 zurück oder wird per permanenter 301-Redirect auf ein neues Linkziel weitergeleitet).
- Seite verfügt über zu wenig qualitativ hochwertigen Inhalt und Google sieht von einer Indexierung ab.
Um nun herauszufinden, warum bestimmte URLs von Dir nicht indexiert sind, tauchen wir nun etwas tiefer in den Abdeckungsbericht in der Google Search Console ein. Dieser teilt die nicht indexierten Seiten in bestimmten Kategorien ein.
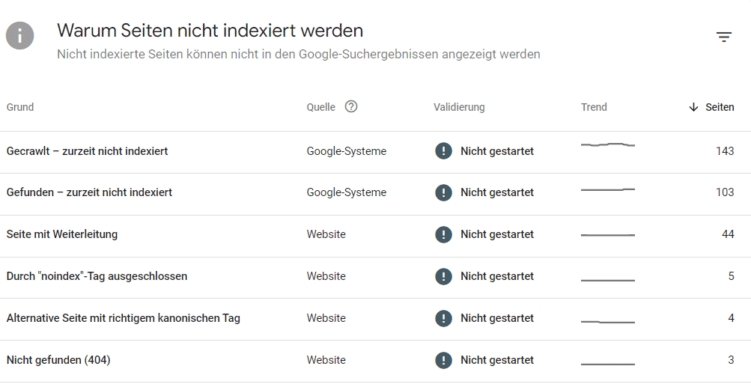
Ein Blick in die Gründe, warum Seiten nicht indexiert werden.
Nachfolgend beleuchten wir einige der häufigsten Berichte:
- Gecrawlt – zurzeit nicht indexiert:
- Diese URLs wurden von Google bereits gecrawlt, aber noch nicht indexiert.
- Das können Inhalte sein, die aber keinen Mehrwert liefern, wie z. B. Duplicate Content, veraltete Inhalte, Thin Content-Pages oder Seiten, die kaum intern verlinkt sind.
- Gefunden – zurzeit nicht indexiert:
- Diese URLs hat Google bereits gesehen, aber noch nicht gecrawlt, sprich heruntergeladen und gerendert.
- Ein potenzieller Grund kann eine Vielzahl an neuen Inhalten auf einmal sein, die das Crawling-Budget einer Website übersteigen und deshalb (erstmal) nicht indexiert werden.
- Seite verfügt über zu wenig qualitativ hochwertigen Inhalt, z. B. kann dies der Fall sein bei automatisiert erstellten Inhalten oder bei Produktdetailseiten in E-Commerce Shops, welche sehr ähnlich sind. Google erkennt dabei URL-Muster. Wenn ein Teil dieser Muster gecrawlt und kein Mehrwert erkannt wird, können diese URLs in dem Bericht „Gefunden – zurzeit nicht indexiert“ landen und Google verzichtet auf weitere Crawlings ähnlicher URLs.
- Duplikat – vom Nutzer nicht als kanonisch festgelegt:
- Hierbei findet Google Duplikate, wie z. B. verursacht durch parametrisierte Versionen einer URL oder wenn Inhalte auf weiteren internen Seiten sowie auf externen Websites zu finden sind, kann Google ebenfalls davon absehen den Inhalt zu indexieren. Das unterstreicht erneut die Bedeutung von einzigartigen Inhalten, die Du Deinen Lesern und Kunden zur Verfügung stellen solltest.
Eine kompakte Auflistung der Crawling-Fehler-Typen inkl. Tipps, wie Du diese beheben kannst, hat mein Kollege Stefan Thaler in seinem Guide-Beitrag „Crawling-Fehler einfach erklärt“ zusammengestellt.
Tipps zur Verbesserung der Indexierung von Inhalten
Das Indexieren von speziell neuen Inhalten kannst Du durch folgende Punkte beschleunigen:
- Abruf von URLs durch Prüftool in der Google Search Console, sodass der Crawler „angestupst“ wird, die Seite zu crawlen und indexieren. Bitte beachte, dass die Indexierungsanträge pro Tag aktuell auf 10 URLs je Nutzer eingeschränkt sind.
- Sitemaps nutzen und dort neue URLs bereitstellen, damit Google diese beim nächsten Abruf auch direkt auffinden kann. Dies kann zum Beispiel in Form von XML oder HTML-Sitemaps geschehen. Anschließend prüfe regelmäßig, ob diese Seiten auch indexiert sind. Stelle zudem sicher, dass in der Sitemap nur URLs eingepflegt werden, die den Status Code 200 haben, indexierbar sind und auch sein sollen – sprich über Mehrwert für den Nutzer verfügen und vor allem Dir Klicks und Conversions besorgen. Hier bist also Du gefragt, damit Google das Crawling Deiner Website effizient gestaltet.
Was ist zudem wichtig, damit Google meine Inhalte indexiert?
- Biete Deiner Zielgruppe einzigartige und aktuelle Inhalte, die über Mehrwert verfügen und sich von der Konkurrenz abheben.
- Verlinke die URLs intern gut auf wichtigen (ranking- und sichtbarkeitsstarken) und thematisch passenden Seiten, um deren Bedeutung zu stärken. Wichtig: aussagekräftige und zur Zielseite passende Anchortexte nutzen!
Low-Performer kicken: wenn Seiten über keinen Traffic verfügen und auch keine Conversions generieren, dann sollte diese Seite auch nicht mehr zur Indexierung bereitstehen (bspw. Ausschluss über das „noindex“-Tag oder durch Zusammenlegen mit anderer Zielseite).
Tipp: Führe regelmäßige URL-Audits durch, um Deine Inhalte qualitativ bewerten zu können und Low-Performer aufzuspüren und zu eliminieren. Gern helfen wir Dir dabei!
Fazit
Die Anzahl an bereits vorhandenen und neuen Website-Inhalten wird immer größer und schreitet immer schneller voran, sodass dies Google Kapazitätsgrenzen und Mittel übersteigt, jede URL herauszufinden, zu crawlen und zu indexieren. Hier wird sich zunehmend auf wichtige Inhalte fokussiert und potenziell eher qualitativ minderwertige Inhalte werden folglich weniger mehr „gesichtet“. Diese Entwicklung stellt die SEO-Welt heutzutage mehr und mehr vor eine wachsende Herausforderung. Es ist nicht mehr nur ein „Kampf“ um beste Rankings, der ausgefochten wird, sondern zukünftig vermehrt um Inhalte überhaupt indexiert zu bekommen. Daher unsere Tipps:
- Viel hilft nicht viel: Mache es Google daher leicht und stelle sicher, dass Google keine irrelevanten URLs crawlt. Je größer Deiner Website ist, desto wichtiger ist die gezielte Crawling- und Indexierungssteuerung.
- Lege den Fokus auf den Mehrwert von Zielseiten und liefere möglichst einzigartige Inhalte, die die Suchmaschine nicht zuvor schon von zig anderen Websites kennt.
- Bremse und korrigiere Deine Erwartungshaltung etwas: Es gelangen möglicherweise nicht alle Inhalte in den Index und möglicherweise auch nicht mehr so rasch.
- Es ist also durchaus OK, wenn nicht alle URLs Deiner Website indexiert werden. Wichtig ist, dass es die richtigen tun und Du alles dafür übernimmst, dass dies auch so bleibt.
Quellen:
- https://searchengineland.com/100-percent-indexing-impossible-385773
- https://twitter.com/methode/status/1420361813833695234
- https://developers.google.com/search/docs/crawling-indexing/large-site-managing-crawl-budget?hl=de
- https://www.seo-suedwest.de/news/podcast/8816-google-indexierung-wird-zum-knappen-gut-seo-im-ohr-folge-258.html
- https://www.seo-suedwest.de/8803-google-fuer-die-meisten-websites-ist-es-inzwischen-schwierig-inhalte-indexieren-zu-lassen.html
- https://www.seo-suedwest.de/7117-google-erklaert-warum-das-indexieren-per-search-console-laenger-dauern-kann-als-frueher.html
Bildnachweis:
Titelbild: ltummy / stock.adobe.com.; Bild 1-5: Screenshots





