Google Indexierung: 10 Fragen und Antworten
Ohne Indexierung kein Ranking. In diesem Blogpost beantworte ich Dir 10 grundlegende Fragen zur Google Indexierung, die für jeden SEO relevant sind.

Der Google Index ist wie ein großes Register – jede findbare URL hat ihren Platz im „Karteikasten“.
#1 Was ist der Google Index?
Der Name „Index“ verrät es schon – er hat unter anderem die Bedeutung „Register“ oder auch „Verzeichnis“. Mit Indexierung ist simpel gesagt gemeint: Die Speicherung einer URL in der Google Datenbank. Diese Datenbank umfasst alle Inhalte, die über die Suche gefunden werden können.
Die Indexierung ist die Grundlage, um über die Google-Suche gefunden zu werden. Sind die Inhalte, mit denen Du gefunden werden möchtest, nicht im großen Google-Karteikasten, existierst Du in den SERPS schlicht nicht. Kurz: Ohne Indexierung kein Ranking.
Vor der Indexierung muss Google die Seiten erst finden, das geschieht über den Prozess des Crawlings: Der Googlebot folgt hierbei internen und externen Verlinkungen.

Crawling und Indexierung hängen eng zusammen – beides ist die Voraussetzung für Rankings.
In einer ersten Verarbeitungsschleife erfolgt der Download des HTML-Dokuments und die Prüfung von Status Codes und Meta Tags. Ist Deine Seite zum Beispiel mit dem Noindex Tag ausgestattet, stoppt der Prozess hier, denn das ist Deine Anweisung: „Bitte indexiere diese Seite nicht“.
Was der Noindex Tag genau ist, liest Du im Seokratie-Guide.
Während des Renderings liest Google das gesamte Dokument mit all seinen Inhalten. Zu den Punkten, die abgearbeitet werden, zählen unter anderen diese:
- Visualisierung der Seite
- Auslesen strukturierter Daten
- Java Script wird ausgeführt
- Prüfung auf Duplicate Content
- und viele weitere.
Wenn dieser Prozess abgeschlossen ist und Deine URL die „Prüfung“ bestanden hat, kann sie in den Google-Index aufgenommen werden und ist prinzipiell über die Google-Suche auffindbar. Warum schreibe ich das im Konjunktiv? Weil diese Schritte zwar die Voraussetzung für die Indexierung sind, aber keine Garantie.
Wichtig: Indexierung bedeutet nicht Ranking und hat nichts mit Rankingfaktoren zu tun – sondern besagt nur, ob eine URL in der Google-Datenbank gespeichert ist.
Mobile First Indexing
Das Verhalten der Nutzer:innen hat sich im letzten Jahrzehnt grundlegend geändert – der Anteil an Suchanfragen über mobile Geräte wie Smartphone hat stark zugenommen. Dieser Veränderung hat sich Google angepasst: 2018 wurde die Mobile-First-Indexierung eingeführt, seit 2021 werden vorwiegend die mobilen Webseitenversionen gecrawlt.
#2 Müssen alle Seiten im Google Index sein?
Nein. Richtig ist: Es sollten alle Deine wichtigen und relevanten Seiten im Index sein, die ein Suchinteresse von Nutzer:innen erfüllen. Seiten, die diese Voraussetzung nicht erfüllen, sollten auch nicht im Google-Index sein. Dazu zählen zum Beispiel Seiten mit identischem Inhalt, aber auch Seiten, die zu Nutzeraccounts gehören und nur nach einem Login erreichbar sind.
In den wenigsten Fällen – zum Beispiel bei sehr kleinen Webseiten – indexiert Google alle URLs einer Domain. Im Schnitt liegt die Indexierungs-Rate zwischen 30 und 60 Prozent, das erklärte John Mueller in den Google Search Central SEO Office Hours vom 19. November 2021.
Richtig ist aber auch: Je größer Deine Webseite, desto größer die Bedeutung der Indexierungssteuerung. Steuerung bedeutet, dass Du Google konkret mitteilst, welche Seiten einen Platz im Index verdienen – und vor allem: welche nicht.
Muss sich der Crawler erst durch Hunderttausende unwichtige URLs arbeiten, bis er zu den wichtigen Seiten kommt, ist Dein Crawlbudget schnell aufgebraucht und relevante Seiten bleiben unentdeckt – und damit ohne Chance auf Indexierung.
Crawling- und Indexierungs-Steuerung hängen eng zusammen:
- Welche Seiten Du nicht indexieren lassen solltest und welche Möglichkeiten Du in Sachen Indexierungssteuerung hast, erklärt Die mein SEO-Kollege Felix ausführlich in seinem Blogpost.
- Was Du über Crawling-Steuerung wissen solltest, liest Du im Blogpost meines SEO-Kollegen Felix L.
#3 Wie prüfe ich, ob eine bestimmte URL indexiert ist?
Du hast zwei Möglichkeiten zu prüfen, ob eine bestimmte Seite von Google indexiert wurde.
Überprüfung via Site Search
Der einfachste Weg führt über die Google-Suche: Gib einfach die URL der Landingpage mit dem Suchoperator „site:“ ein. Ist die Seite indexiert, taucht sie als Suchergebnis auf.
Ist sie nicht im Index, liefert Dir die Suche keine Ergebnisse. Mit dieser Methode kannst Du zudem prüfen, ob bestimmte Inhaltsabschnitte Deiner Seite im Index sind.

Die Site Search der Beispiel URL liefert keine Ergebnisse, das ist ein klarer Hinweis, dass sie nicht im Google Index ist.
Überprüfung via URL Prüftool der Google Search Console
Gib hierfür die URL in das URL-Prüftool der Google Search Console ein. Du findest im Tool am oberen Seitenrand:

Beschreibung: Die überprüfte URL ist indexiert.
Die geprüfte URL ist indexiert – soweit, so gut. Zusätzlich gibt Dir das URL-Prüftool weitere Antworten zu folgenden Fragen:
- Wie hat der Googlebot die Seite gefunden (Sitemap und/oder Verlinkungen)?
- Ist das Crawling grundsätzlich erlaubt?
- Wann wurde die URL zuletzt gecrawlt?
- Wurde die Mobilversion oder die Desktopversion der Seite gecrawlt?
- Kann die Seite indexiert werden?
- Welche URL ist die kanonische und stimmt die von Google ausgewählte kanonische Seite mit der von Dir angegebenen überein?
- Welche strukturierten Daten sind hinterlegt und sind diese technisch fehlerfrei?
- Ist die Seite sicher, wird sie via https-Protokoll abgerufen?

Bei der für dieses Beispiel geprüften URL ist alles in Ordnung, die Seite ist indexiert und hat keine Fehler.
Die weiterführenden Informationen des Prüftools sind vor allem hilfreich, wenn Deine Seite nicht indexiert ist:
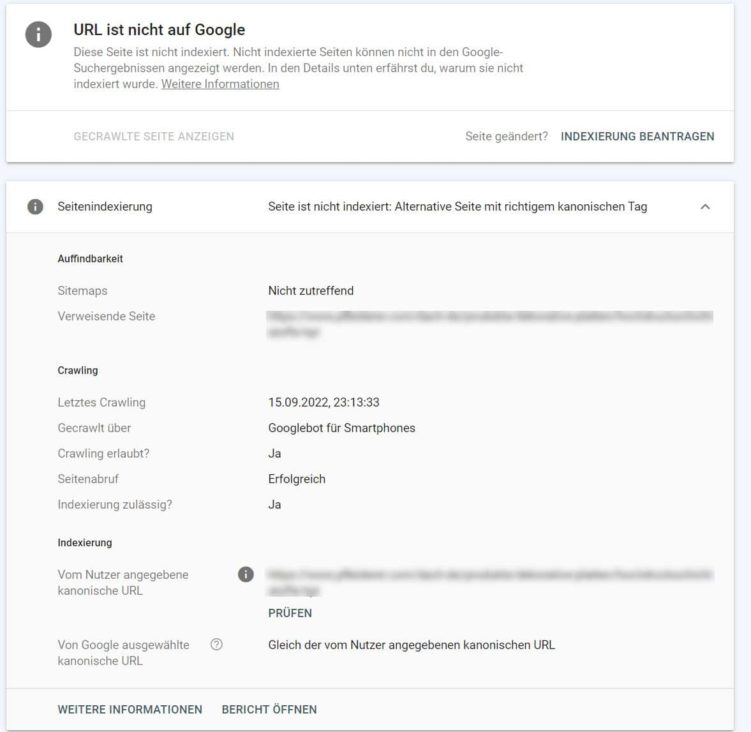
Die geprüfte Seite ist richtigerweise nicht indexiert, denn sie verweist via Canonical auf die Original-URL.
Mit dem URL-Prüftool kannst Du außerdem die Live-URL testen und prüfen, ob der Bereich „Above the Fold“ korrekt gerendert wird:

Im Reiter „Screenshot“ siehst Du die gerenderte Seite Deiner Test-URL.
#4 Wie prüfe ich den Status meiner gesamten Website?
Die Google Search Console liefert Dir nicht nur einen Überblick über die indexierten und nicht-indexierten URLs Deiner Website. Sie zeigt Dir auch mögliche Gründe auf, warum Seiten nicht in den Index aufgenommen wurden:

Mögliche Gründe für die Nicht-Indexierung findest Du in den jeweiligen Abdeckungsberichten.
Gründe für die Nicht-Indexierung sind zum Beispiel:
- Duplicate Content: URLs mit identischem Inhalt
- weitergeleitete URLs
- kanonisierte URLs
Zudem findest Du im Bericht Angaben zu Seiten, die der Googlebot zwar gecrawlt, aber nicht indexiert beziehungsweise gefunden und nicht einmal gecrawlt hat.
Mehr zum Status „Gecrawlt/Gefunden – zurzeit nicht indexiert“ erfährst Du in meinem Blogpost.
Ich empfehle Dir außerdem die Quick Tipp-Videoreihe zur Google Search Console auf YouTube. Meine SEO-Kollegin Nora nimmt sich hier (unter anderem) den einzelnen Berichten zur Index-Abdeckung an.
Die Google Search Console API für den Screaming Frog ist eine zweite Möglichkeit, den Indexierungsstatus zu überprüfen.
API: Abkürzung für „Application Programming Interface“, eine Programmierschnittstelle, die es zwei Systemen erlaubt, miteinander zu kommunizieren und Daten auszutauschen.
Angenommen, Du möchtest 150 Deiner wichtigsten Seiten auf ihren Status bei Google überprüfen. Mit dem URL-Prüftool dürfte das ziemlich lange dauern, auch der Abdeckungsbericht hilft Dir hier nur bedingt weiter.
Effizienter gewinnst Du in diesem Fall Erkenntnisse, wenn Du die URLs im Listenmodus mit dem Screaming Frog und der API crawlst.

Mit dem Screaming Frog kannst Du die URLs nach Indexierungsstatus gruppieren.
Dieser Bericht liefert Dir gebündelt dieselben Informationen wie die Google Search Console, jedoch übersichtlich nach URL gebündelt:
- Klicks, Impressionen und Position
- Zusammenfassung des Status
- Angaben zur Abdeckung: Aus welchem Grund ist eine URL nicht indexiert?
- Zeitpunkt des letzten Crawls / Tage seit dem letzten Crawl
- Wie wurde gecrawlt – via Mobile oder Desktop Agent?
- War der Seitenabruf erfolgreich?
- Ist die Indexierung grundsätzlich erlaubt?
- Vom Nutzer gewählte und die von Google bestimmte kanonische Seite
- Einschätzung und Fehler zur mobilen Benutzerfreundlichkeit
- Einschätzung und Fehler zur AMP-Version
- Angaben zu den Arten von strukturierten Daten & gefundene Fehler

Mit Exel kannst Du die Daten übersichtlich aufbereiten, hier siehst Du die URLs einer Domain, die gecrawlt, aber nicht indexiert sind.
#5 Wie beantrage ich die Indexierung einer Seite?
Hast Du eine Seite überarbeitet oder möchtest das Crawling und die Indexierung eines neuen Inhalts anstoßen, dann beantragst Du das im Prüftool der Google Search Console.
Achtung: Du kannst das Crawling anstoßen, leider bedeutet das nicht automatisch, dass der Bot sofort vorbeikommt.

Nach dem Absenden des Formulars siehst Du den Status „Indexierung beantragt“.
#6 Wie lange dauert es, bis meine Seite indexiert ist?
Wieviel Zeit vergeht, bis Dein neuer oder überarbeiteter Inhalt indexiert ist, lässt sich nicht vorhersagen. Google selbst macht hierzu sehr schwammige Angaben:
„Nachdem Sie eine neue Seite online gestellt haben, kann es einige Zeit dauern, bevor sie gecrawlt wird. Eine Indexierung dauert in der Regel noch länger. Die Gesamtdauer kann zwischen ein oder zwei Tagen und einigen Wochen liegen.“
Um Crawling und Indexierung nicht zu verzögern, solltest Du dem Googlebot das Crawling und die Bewertung so leicht wie möglich machen:
- Vermeide grundsätzliche technische Probleme wie Serverfehler, sehr langsame Ladezeiten und Soft 404-Fehler. Diese wirken sich negativ auf Dein Crawlbudget aus und reduzieren die Kapazität für das Crawling wichtiger Seiten.
- Zeige dem Googlebot den Weg: Achte darauf, dass Du eindeutig kommunizierst, welche Seiten indexiert werden sollen und welche nicht. Nutze hierfür das Meta Tag „Noindex“ und „Index“, kennzeichne URL-Duplikate mit dem Canonical Tag und konfiguriere die txt.
- Stelle ein oder mehrere segmentierte Sitemaps zur Verfügung. Mit dem Tag „lastmod“ kannst Du Google mit der Sitemap auf Aktualisierungen des Inhalts hinweisen.
- Erstelle einmalige und für Deine Nutzer:innen relevante Inhalte.
- Achte bei der Seitenstruktur darauf, dass wichtige Seiten gut intern verlinkt sind und die Klickpfadlänge möglichst kurz ist.
#7 Kann ich die Google-Indexierung beschleunigen?
Du kannst Google nicht zwingen, Deine Seiten direkt und sofort zu indexieren. Was Du bei sehr wichtigen neuen oder aktualisierten Inhalten tun kannst: Beantrage die Indexierung über das Prüftool manuell.
Google sagt zwar offiziell, dass mehrmaliges Einreichen einer URL den Crawl- und Indexierungs-Prozess nicht beschleunigt, wir haben andere Erfahrungen gemacht. Das erneute und mehrmalige Einreichen kann die Indexierung durchaus beschleunigen.
Gut zu wissen: Die Anzahl der Indexierungsanträge pro Tag in der Google Search Console ist auf 10 URLs in 24 Stunden begrenzt.
Google Indexing API
Mit Hilfe der Google Indexing API kannst Du Google direkt mitteilen, wenn sich Seiteninhalte geändert haben oder Du Seiten entfernt hast. Leider ist das aktuell ausschließlich für Inhalte möglich, die strukturierte Daten des Typs „Job Posting“ oder „Broadcast Event“ (Auszeichnung eines Videos) enthalten. Also solche Inhalte betreffen, bei denen eine schnelle Aktualisierung wichtig für die Qualität des Suchergebnisses ist. Mehr Infos zur Indexing API findest Du hier.
#8 Warum indexiert Google meine Seite nicht?
Google indexiert Deinen Inhalt nicht? Hierfür gibt es viele Gründe, diese 4 solltest Du in jedem Fall prüfen und ausschließen:
Grund 1: Du hast es verboten.
Prüfe, ob die Seite das Meta Tag „Noindex“ hat oder in der robots.txt vom Crawling ausgeschlossen ist. Ist hier alles in Ordnung, prüfe, ob die URL via Canonical Link auf eine andere URL verweist.
Grund 2: Du machst uneindeutige oder keine Angaben.
Gibst Du Google bei einer großen Webseite keine Hinweise zu Deinen Wünschen in Form von Canonicals, robots.txt und Noindex-Tag, dann crawlt der Bot mühselig viele URLs und ordnet diese selbst ein. Wenn dann viele irrelevante Seiten dabei sind, fressen diese Dein Crawlbudget schnell auf.
Fehlerhafte und widersprüchliche Angaben auf Deiner Seite können ebenso dazu führen, dass Seiten nicht in den Google-Index kommen. Ein Beispiel: Eine URL A wird in der Sitemap gesendet, verweist jedoch via Canonical auf eine andere URL B. Diese ist nicht in der Sitemap. Zum einen ist es für Google schwierig URL B zu finden und zu crawlen. Zum anderen kann es aufgrund der Fehler sein, dass URL B (die wichtige URL) nicht indexiert wird. Neben Canonicals sind falsche hreflang-Anweisungen in Kombination mit Canonicals häufige Fehlerquellen. Ergo: Stelle sicher, dass Google möglichst nur relevante URLs crawlen und indexieren kann.
Grund 3: Die Seite ist für Google schwer auffindbar.
Wenn die betreffende URL keine eingehenden internen oder externen Links hat, dann wird sie als „verwaiste URL“ bezeichnet. Da das Crawling über Hyperlinks stattfindet, kann diese Seite vom Googlebot nicht gefunden – und damit nicht indexiert werden.
In dem Fall solltest Du
- für eine bessere interne Verlinkung von trafficstarken Seiten sorgen.
- die Seite in die Sitemap aufnehmen.
- sicherstellen, dass Deine internen Verlinkungen immer das „follow“-Attribut besitzen.
Grund 4: Die Seite hat nur geringe Qualität.
Überprüfe, ob der Inhalt der Seite den qualitativen Anforderungen entspricht, Relevanz besitzt und eine gute Erfahrung für die Nutzer:innen bietet. (Stichwort Ladezeit und Navigation).
#9 Warum ist meine Seite indexiert, obwohl ich das verboten habe?
Manchmal kommt es vor, dass Seiten indexiert sind, obwohl sie eigentlich via robots.txt vom Crawling ausgeschlossen sind. Das ist dann der Fall, wenn eine Seite bereits im Google-Index ist und Du sie erst danach in der robots.txt ausschließt. Nun kann Google nicht mehr crawlen, denn das hast Du ja verboten – dennoch sind die Seiten im Index.
![]()
Du kannst diese Kollision vermeiden, indem Du vor dem Ausschluss bestimmter URLs überprüfst, ob diese Seiten schon indexiert sind. Wenn ja, solltest Du hinterfragen, aus welchen Gründen sie indexiert sind und ausschließen, dass sie inhaltliche Relevanz haben.
Trotz Sperrung indexierte URLs sind meist kein kritisches Problem: Mit der Zeit begreift Google, worum es Dir geht – und die URLs verschwinden aus dem Index:

Bei dieser Webseite wurden eine Menge Filter-URLs in der robots.txt gesperrt. Die Anzahl der bemängelten Seiten nimmt nach kurzer Zeit schnell ab.
#10 Wie entferne ich eine Seite aus dem Google Index?
Um Seiten dauerhaft aus dem Google Index zu löschen, musst Du sie entweder aus dem Crawling ausschließen oder auf „Noindex“ setzen – alle anderen Maßnahmen sind entweder nicht dauerhaft oder nicht zwingend für Google.
Willst Du eine URL vorübergehend aus dem Index entfernen, kannst Du in der Google Search Console einen Antrag stellen.

Du hast zwei Möglichkeiten:
- Entweder die URL für 6 Monate von den Suchergebnissen auszuschließen oder
- die im Cache gespeicherten Informationen zum Snippet und der Seite bis zum nächsten Crawl zu löschen.
Mit dieser Funktion unterbindest Du das Crawling nicht, sondern stellst lediglich sicher, dass diese Seite für circa 6 Monate nicht in den Suchergebnissen erscheint. Ich persönlich habe diese Funktion noch nie genutzt, sie kann in bestimmten Fällen aber sinnvoll sein. Unter anderem, wenn Du ein Ergebnis aus rechtlichen Gründen schnell aus den SERPS entfernen musst.
Fazit
Damit Google Deine wichtigen Seiten zuverlässig indexiert, sind diese Punkte essenziell:
- Betrachte das Crawling und die Google Indexierung als wichtige Basis – beide sind zwingende Voraussetzungen für Deine Rankings.
- Mache eindeutige und technisch korrekte Angaben zum Crawling und der Indexierung auf Deiner Website. So findet der Bot Crawlbudget-schonend den richtigen Weg. Je größer Deine Website, desto wichtiger ist das.
- Erstelle einmalige, relevante und nutzerzentrierte Inhalte – und fokussiere Dich in Sachen Indexierungs-Steuerung und -Monitoring auf den Erfolg dieser
Welche Erfahrungen, Hindernisse und Erfolge hast Du in Sachen Indexierung schon erlebt? Schreib mir gern einen Kommentar. Und wenn Du gerade vor einem größeren Indexierungs-Problem stehst, helfen wir Dir bei Seokratie gern dabei, Ursachen und vor allem die Lösungen dazu zu finden.
Bildrechte: Titelbild ©yossarian6, Grafik: Seokratie, Bild 3-13: Screenshots






Liebes Seokratie-Team,
euer Blog ist einfach spitze.
Vielen Dank für den massiven Mehrwert den ihr hier liefert.
Beste Grüße aus Wiesbaden