Canonical Tag: So schützt Du Dich vor Duplicate Content
Das Canonical Tag – auch Canonical-Link-Attribut genannt – ist ein Hilfsmittel, um mehrere identische Inhalte zusammenzufassen. Es ist ein Weg, Duplicate Content zu vermeiden. Wie das genau funktioniert und in welchen Fällen Du Canonical Links verwendet solltest, zeige ich Dir in diesem Blogpost. Plus: Die häufigsten Canonical-Fehler.

Das Canonical Tag zeigt Google, wo sich das Original versteckt.
Inhalt
Was ist das Canonical Tag?
Canonical Tags helfen Dir dabei, die rankende URL Deiner Seite zu steuern, wenn Du identische Inhalte auf der Webseite hast. Das ist zum Beispiel der Fall, wenn ein Inhalt auf mehreren URLs angezeigt wird.
Technisch gesehen ist das Canonical Tag ein Link im Quelltext einer Seite. Der Link der Duplikate zeigt dabei auf die Original-URL (sogenannte kanonische URL). Damit wird sie als diejenige URL gekennzeichnet, die Du im Index bevorzugen möchtest. Auch die kanonische URL besitzt einen Canonical: Dieser verweist jedoch auf sich selbst, man spricht von einem Self referencing Canonical.

Im Sprachgebrauch hat sich der Name Canonical Tag eingebürgert. Richtigerweise heißt es jedoch Canonical Link.
Warum ist das Canonical Tag für SEO wichtig?
Hast Du auf Deiner Website mehrere inhaltlich identische Contents oder sehr ähnliche Inhalte, kann Google nicht immer klar erkennen, welche URL relevant ist und ranken sollte.
Beispiele für identische Inhalte sind URLs mit und ohne Parameter oder unterschiedliche Formate wie Druck- oder PDF-Versionen einer HTML-Seite.
Anstatt sich für Deine bevorzugte Seite zu entscheiden, kann es passieren, dass Google:
- alle Versionen indexiert, dann hast Du Duplicate Content im Google-Index. Warum das nicht gut ist, kannst Du in Felix‘ Blogpost zu Duplicate Content
Gleichzeitig ranken alle diese Versionen nicht so gut, wie es eine einzelne „Fassung“ könnte, wenn es nur sie gäbe. - einen der Inhalte auf Top-Positionen rankt, jedoch nicht Deinen präferierten. Zum Beispiel eine PDF-Version Deiner Landingpage.
- keine Version indexiert, sondern alle aus dem Index ausschließt.
Mit dem Canonical Tag zeigst Du Google: Hier gibt es eine Hauptversion der Inhalte, bitte indexiere diese, übertrage die Signale der Duplikate auf diese und ranke nur das Original. Das Canonical Tag ist also ein wichtiges SEO-Instrument.
Wichtig zu wissen: Das Canonical Tag ist lediglich eine Empfehlung für Google und nicht zwingend. Das bedeutet: Google entscheidet in letzter Instanz, welche URL die kanonische ist und welche ausgeschlossen werden soll. Welche URL Google als kanonisch ansieht, zeigt Dir Google netterweise in der Search Console unter dem „URL Prüftool“.
Wie binde ich das Canonical Tag korrekt ein?
Es gibt zwei Möglichkeiten, das Canonical Tag auf Deiner Website technisch einzubinden. Bei beiden Integrationsarten empfiehlt Google, absolute URLs zu verwenden und keine relativen.
rel=“canonical“ Link-Tag im Head-Bereich des HTML Codes
In HTML-Dokumenten wird das Canonical Tag im Head-Bereich der Seite eingebunden:
- Die Original-Ressource verweist auf sich selbst (Self referencing Canonical)
- Duplikate verweisen auf die kanonische URL.
Beispiel: Die Seite https://www.soliver.de/c/damen/schuhe/stiefeletten/ verweist mit dem Canonical Link auf sich selbst als kanonische URL. So sieht das im Quellcode aus.
<link rel=“canonical“ href=“ https://www.soliver.de/c/damen/schuhe/stiefeletten/“ />
Aufgeschlüsselt besagen die einzelnen Elemente Folgendes:
- <link: öffnet das Link-Tag
- rel=“canonical“: ist das eigentliche Canonical-Attribut
- href=“ https://www.soliver.de/c/damen/schuhe/stiefeletten/“ : ist der Link zur kanonischen URL
- />: schließt das Link-Tag
rel=“canonical“ im HTTP-Header
Bei nicht-HTML-Dateien wie zum Beispiel PDFs gibt es keinen Head-Bereich, hier brauchst Du eine alternative Möglichkeit: Du bindest das Canonical Tag im http-Header der Seite ein.
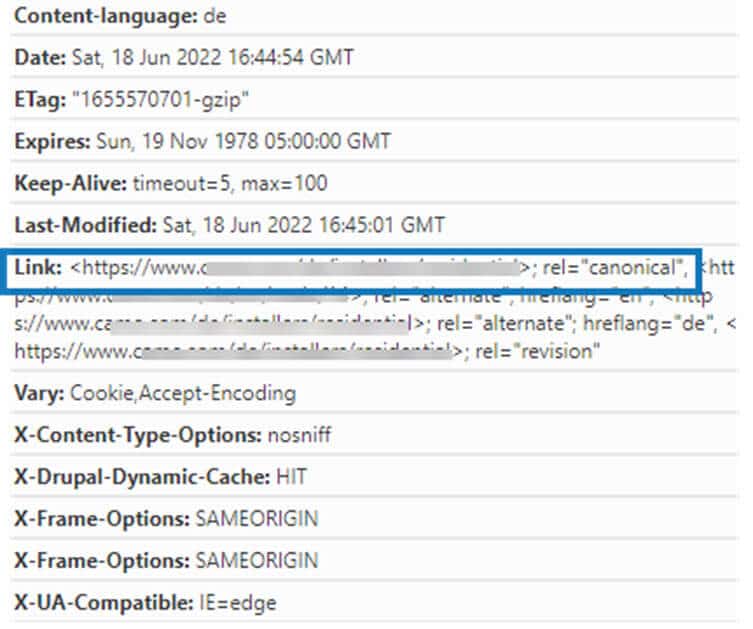
So sieht das Canonical Tag im http-Header aus.
Um das Canonical Tag eines PDFs in den http-Header einzufügen, ergänzt Du die .htaccess-Datei um den entsprechenden Code:
<Files "inhalt-a.pdf"> Header add Link '< "https://wwww.beispiel.com/inhalt-a/ >; rel="canonical" ' </Files>
Achtung: Im Gegensatz zu HTML darfst Du Anführungszeichen in der .htaccess pro Code-Teil nur einmal verwenden. Mithilfe von Maskierungszeichen wie \ oder Hochkomma kannst Du das umgehen.
Aufgeschlüsselt bedeuten die Elemente:
- <Files: öffnet das Tag, hier steht der Dateiname Deines PDF-Dokuments.
- Header add Link < https://wwww.beispiel.com/inhalt-a/ >; rel=“canonical“ : ist die kanonische URL und das Attribut an sich.
- />: schließt das Tag
Aufgelöst siehst Du dann im http-Header der URL folgendes:
Link: <https://www.beispiel.com/inhalt-a/>; rel=“canonical“>
Canonical Tags prüfen: So geht’s
Du hast verschiedene Möglichkeiten zu prüfen, ob das Canonical Tag einer URL oder die Canonical Tags der ganzen Domain richtig verwendet werden. Was noch wichtiger ist: Ob Google Deinen Canonical-Vorschlägen folgt oder nicht.
Screaming Frog: Sind die Canonicals korrekt integriert?
Mit dem Screaming Frog kannst Du zwei Dinge relativ einfach herausfinden:
- Siehst Du ob die Tags technisch richtig verbaut sind.
- Kannst Du Dir schnell einen Überblick über den Gesamt-Status einer Domain verschaffen: Gibt es überhaupt Canonicals? Welche Arten von Seiten haben Canonical Tags? Wichtig ist auch, ob die Umsetzung in sich schlüssig ist.
Problematisch ist zum Beispiel, wenn hreflang-Verweise auf kanonisierte URLs zeigen. Oder wenn alle internen Links auf kanonisierte anstatt auf kanonische URLS verweisen.
So gehst Du vor:
1. Crawle die Domain.
2. Im Screaming Frog wählst Du den Reiter „Canonicals“.
3. Mit Hilfe der Filter findest Du technische Fehler wie mehrere oder nicht indexierbare Canonicals. Außerdem siehst Du auf einen Blick, welche URLs kanonisiert sind und ob Self referencing Canonicals eingebunden sind.

3 Wege, den Canonical-Status einzelner URLs zu prüfen
Willst Du lediglich den Status einer einzelnen URL prüfen, gibt es mehrere Wege:
-
- Das Browser Plugin „Link Redirect Trace“ zeigt Dir übersichtlich an, ob ein Canonical verwendet wird und wenn ja, auf welche URL es verweist.
- Um zu überprüfen, ob Dein Canonical Tag von Google akzeptiert wird, kannst Du den „info:“ Such-Operator in der Google-Suche verwenden. Gib hinter den Operator die URL des Duplikats an, als Ergebnis sollte dann deren kanonische URL erscheinen:
 Wenn Du mehr zum Thema Google Suchoperatoren wissen willst, dann schau Dir den Blogpost meines Kollegen Stefan an.
Wenn Du mehr zum Thema Google Suchoperatoren wissen willst, dann schau Dir den Blogpost meines Kollegen Stefan an. - Nutze das Linktool der Google Search Console: Einfach die URL, die Du prüfen möchtest, einfügen und Du siehst auf einen Blick den Indexierungs- und Canonical-Status:

Folgt Google generell meiner Canonical-Strategie?
Im Abdeckungsbericht der Google Search Console findest Du über den Tab „Ausgeschlossen“ diejenigen URLs, die Google aktuell aus verschiedenen Gründen nicht indexiert.
Im Idealfall, wenn Google all Deinen Wünschen Folge leistet, sind unter dem Punkt „Alternative Seite mit richtigem kanonischen Tag“ Deine kanonisierten URLs gelistet:

Als SEOs wissen wir aber: Google folgt niemals all unseren Wünschen, deswegen wirst Du auch URLs finden, bei denen Google Deinen Vorschlag ignoriert und eine andere Seite als Deine kanonische bevorzugt. (roter Rahmen im Screenshot)
Das allein ist noch kein Grund zur Panik. Aufhorchen solltest Du, wenn nur wenige Deiner Canonicals von Google befolgt werden. In dem Fall gilt es herauszufinden:
Warum betrachtet Google andere URLs als Deine präferierten als indexierungswürdig?
Das ist dann der Fall, wenn der Bot annimmt, dass diese Seiten relevant für die Suchenden sind, unter anderem weil
- die kanonisierten Varianten der URLs wesentlich mehr Traffic erhalten als die kanonische Seite.
- viele interne Links auf die kanonisierten URLs zeigen. Besonders wenn Du von trafficstarken Seiten auf kanonisierte URLs verlinkst, nimmt Google an, dass diese Seiten relevanter als die Originale sind.
- externe Domains auf Deine kanonisierten Seiten verlinken.
- hreflang-Tags auf kanonisierte URL verweisen.
Je konsistenter und eindeutiger (und natürlich technisch korrekt) Du Google mitteilst, welche Seiten Deiner Domain wichtig sind, desto eher wird der Suchmaschinen-Bot Deinem „Vorschlag“ folgen.
Auch wenn aktuell alles im grünen Bereich ist, solltest Du regelmäßig einen Blick auf die Entwicklung der ausgeschlossenen URLs werfen, um Probleme rechtzeitig zu erkennen.
Anwendungsfälle für den Canonical Link
Die Anwendungsfälle für Canonical Tags sind überschaubar. Bei diesen vier Szenarien können sie Deiner Webseite helfen:
#1 Dynamische URLs
Viele Webseiten verwenden dynamische URLs, die den Inhalt der Seite nicht maßgeblich verändern: Zum Beispiel Session-IDs oder verschiedene Darstellungen einer Kategorieseite.
Im Beispiel siehst Du eine Kategorieseite von Hagebaumarkt, die über mehrere URLs erreichbar ist: Einmal ohne und einmal mit einem Parameter.

Das ist ein Positivbeispiel für die Verwendung des Canonical Tags bei dynamischen URLs: Der angehängte Parameter verändert den Inhalt der Seite nicht, also zeigt der Canonical der Parameter-URL auf das Original. Der Canonical der Originalseite zeigt auf sich selbst.
Wenn Dein Shop sehr viele Produkte hat und es jede Menge Filter-URLs gibt, dann hat der Einsatz des Canonical Tags einen Nachteil: Google wird diese Seiten weiterhin crawlen – und jeweils der Canonical URL folgen – was Dein Crawlbudget belastet. Die Alternativen – wie zum Beispiel die Linkmaskierung via PRG-Pattern oder die Verwendung des noindex Tags – erklärt Dir mein SEO-Kollege Stefan Pusch in seinem Blogbeitrag „Facettensuche und SEO“
#2 Inhalte sind unter mehreren URLs erreichbar
Systembedingt kann es vorkommen, dass Deine Artikel unter verschiedenen URLs erreichbar sind, zum Beispiel wenn Du sie in unterschiedliche Kategorien einsortierst:
- Dein-shop.de/roecke/lila-rock &
- Dein-shop.de/sommermode/lila-rock
Auch in diesem Fall solltest Du Dich für eine kanonische URL entscheiden und die Variante per rel=“canonical“ auf diese verweisen lassen.
Aber: Sofern es technisch und in Sachen Usability möglich ist, ist es – bis auf Einzelfälle – immer am besten nur eine Version eines Inhalts zu haben. Die „zweitbeste“ Variante ist es, eine 301-Weiterleitung zu verwenden. Der Canonical ist die Notlösung. Je nach Fall kann es sogar sinnvoller sein, das Duplikat auf noindex zu setzen.
Wenn Deine Inhalte unter mehreren URLs erreichbar sind, zum Beispiel mit „www“, ohne „www“, mit Trailing-Slash, ohne Trailing-Slash UND Deine Entwickler eine 301-Weiterleitung technisch NICHT umsetzen können, solltest Du das Canonical-Attribut verwenden, um eine bevorzugte Version festzulegen.
Mit dem Statuscode 301 teilst Du den Suchmaschinen mit, dass die Seite dauerhaft verschoben ist. Google crawlt nur noch das Weiterleitungsziel, nicht mehr die Ursprungsseite. Auch die User werden direkt auf die neue Seite geführt. Verwendest Du Canonical Tags, crawlt Google die Duplikate weiterhin und die User können diese Seiten weiterhin aufrufen. Der Canonical ist für Google nur ein Hinweis – dem es in der Regel zwar folgt, aber der für Google nicht zwingend ist. Eine 301-Weiterleitung kann dagegen von Google nicht ignoriert werden.
#3: Inhalte in verschiedenen Formaten
In einigen Fällen ist es sinnvoll, Deine Inhalte in verschiedenen Formaten anzubieten – zum Beispiel eine Checkliste zusätzlich als Druck- oder PDF-Version. Dann kann es passieren, dass Google die aus Deiner Sicht „falsche“ Version bevorzugt.
Damit statt dem PDF das HTML-Dokument rankt, kannst Du im http-Header des PDFs einen Canonical Link auf die HTML-URL setzen. Außerdem sollte im HTML-Dokument der Canonical Link auf die eigene URL zeigen. Damit ist für Google verständlich: Das PDF ist die „Kopie“ des HTML-Dokuments.
#4: Inhalte auf anderen Domains
Ein Sonderfall sind Cross-Domain-Canonicals. Wenn Du Deine Inhalte auch auf anderen Domains veröffentlichst, kannst Du von Ihnen einen Canonical Tag auf den Originalinhalt Deiner Webseite zeigen lassen. Sicher ist, dass Duplicate Content so vermieden wird.
Die zugehörigen, positiven User-Signale können dabei auf Deinen Ursprungsartikel übertragen werden, so Rand Fishkin bei Moz: „So something above 90% of the link authority and ranking signals will transfer […].“
Achte bei Cross-Domain-Canonical Tags darauf, dass der Inhalt der Seite sich nicht ändert – also Text, Bilder und Videos müssen (fast) identisch sein. Auch die Verlinkungen im Content sollten im besten Fall übereinstimmen. Dass sich URL, Design und Navigation ändern, ist in Ordnung. Auch der Meta-Title kann sich unterscheiden.
Hreflang und Canonical Tags hängen stark zusammen. Akzeptiert Google eines von beiden nicht mehr, kann es Dir passieren, dass beide Anweisungen ignoriert werden. Pass auf, dass jede Länderversion den Canonical auf die eigene Seite hat. Generell sollten nur kanonische URLs einen hreflang Tag haben. Wie Du Canonicals und hreflang zusammen verwendest, kannst Du im Blogpost meiner SEO-Kollegin Luisa zu hreflang nachlesen.
Don’t: 7 häufige Canonical-Fehler
Wir sehen in unseren SEO-Analysen immer wieder dieselben Fehler, die beim Einsatz von Canonicals auftreten. Das sind die häufigsten:
#1 Die kanonische URL ist nicht indexierbar/erreichbar
Stelle immer sicher, dass die kanonische URL erreichbar ist. Einfach überprüfen kannst Du das, indem Du die Statuscodes der Canonical-Ziele checkst, zum Beispiel über einen Crawl.
#2 Gleichzeitiger Einsatz von rel=“canonical“ & „noindex“
Der gleichzeitige Einsatz von Canonicals und noindex ist unerwünscht und zwar aus folgendem Grund: Während der Canonical besagt, dass zwei Seiten identisch sind, besagt das noindex Tag, dass die Seite nicht indexiert werden soll. Google muss sich dann folgende Frage stellen: Wenn diese Seite nicht indexiert werden soll, dann ihr Original auch nicht, oder?
#3 Canonical Links auf Paginierungsseiten
Verwende keine Canonicals auf hinteren Paginierungsseiten, um auf die erste Seite zu verweisen. Die Seiten sind nicht identisch, der Inhalt ist unterschiedlich. Ergo ergibt ein Canonical Tag keinen Sinn.
#4 Mehr als ein Canonical
Stelle sicher, dass Du immer nur ein Canonical Tag auf jeder Seite hast. Verwendest Du mehrere, wird Google einfach alle Canonical Links ignorieren.

s.Oliver hat bei dieser URL 2 Canonical Links integriert. Das solltest Du nicht nachmachen.
#5 Canonical Tag bei zu unterschiedlichen Seiten
Nutze das Canonical-Attribut nur, wenn die Seiten sich sehr ähnlich (zu 98% gleich) sind. Unterscheiden Sie sich zu stark, wird Google Deine Canonical-Anweisung nicht beachten.
#6 Canonical Link im <body> statt im <head>
Der Canonical sollte immer im Head-Bereich beziehungsweise http-Header stehen. Fügst Du ihn woanders ein, wird Google ihn ignorieren.
#7 Kanonisierte URLs in der Sitemap
In der Sitemap sollten nur URLs zu finden sein, von denen Du möchtest, dass Google sie indexiert. Deswegen haben kanonisierte Seiten in der Sitemap nichts zu suchen.
Fazit
Canonical Tags sind wichtig für SEO, vor allem im e-Commerce Bereich, wo viele Filter-URLs entstehen. Sie geben Dir die Möglichkeit, Google den richtigen Weg zu Deinen wichtigen Seiten zu zeigen. Und auch wenn Google diesem Weg nicht immer 100% folgt – ohne Canonicals würde sich unser Lieblingsbot wahrscheinlich im URL-Dschungel verirren – zum Leidwesen Deiner SEO-Performance.
Natürlich sind Canonical Tags kein Allheilmittel. In vielen Fällen gilt deswegen: Wäge mögliche technische Alternativen wie das noindex Tag, 301-Weiterleitungen und Co. gegeneinander ab.
Welche guten oder auch schlechten Erfahrungen hast Du mit Canonicals gemacht? Schreib mir gerne einen Kommentar oder frag mich, wenn Du akut vor einer kanonischen Herausforderung stehst.
Bildrechte: Titelbild ©yuriyzhuravov, Adobe Stock, ©Grafik GraphicGrid, Adobe Stock





