Crawlingsteuerung bei Onlineshops: Aber wie(so)?
Besonders bei großen Onlineshops mit vielen Tausenden bis hin zu Millionen URLs wird ein SEO-Thema besonders spannend: Crawlingsteuerung. Bei großen Seiten darf das Crawling nicht einfach sich selbst überlassen werden. Kleine technische Details können hier große Auswirkungen haben. Wie solltet ihr also das Crawling steuern? Und warum überhaupt? Wir haben die wichtigsten Punkte zusammengestellt.
Wisst ihr eigentlich, wie es auf eurer Website kreucht und fleucht?
Versteht Euer Crawlbudget
Bei wirklich großen Seiten – wie es die meisten Shops sind – ist es wichtig zu verstehen, dass es ein sogenanntes Crawling-Budget gibt. Suchmaschinen stehen nicht unbegrenzt Ressourcen zur Verfügung, um alle URLs der Welt regelmäßig zu crawlen. Euer Ziel muss daher sein, Suchmaschinen nur oder zumindest vornehmlich die URLs crawlen zu lassen, die wirklich wichtig sind. Wie häufig Google Eure Seite crawlt, seht Ihr in Eurer Search Console im Bericht Crawling-Statistiken.
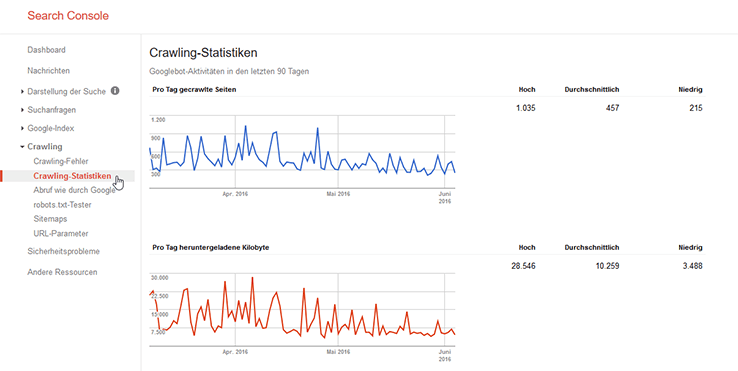
Noch detailliertere Infos bekommt Ihr übrigens, wenn Ihr einzelne Verzeichnisse in der Search Console einreicht, um Unterschiede und Unregelmäßigkeiten zu finden. (Richtigstellung: Genau die Crawling-Statistiken funktionieren da nicht, aber alle anderen Crawling-Reports) Unregelmäßigkeiten können unter anderem folgende Ausschläge sein:
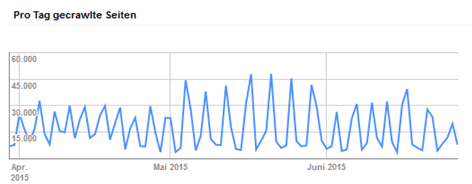
Über eine Analyse der Logfiles haben wir in diesem Fall festgestellt, dass sich der Bot der Google Bildersuche in Unmengen von unnötigen Bilder-URLs verlaufen hat. Das soll so natürlich nicht sein, Daher galt es, dort anzusetzen und die Bilder-URLs zu reduzieren.
Wenn es um Crawlingsteuerung geht, ist eine solche Logfile-Analyse enorm wichtig. Nur so könnt Ihr die Aktivitäten der Crawler wirklich nachvollziehen, überwachen – und steuern.
Aber wie steuert Ihr jetzt genau das Crawling? Ärmel hochkrempeln, jetzt geht’s los!
Plant Eure Seitenarchitektur logisch
Die Grundlage für einen gut optimierten und crawlbaren Shop ist eine saubere und logische Seitenarchitektur. Dazu gehören viele Faktoren. Besonders wichtig ist eine sinnvolle URL-Struktur, die über sprechende Verzeichnisse die Struktur der Seite widerspiegelt. Hier gilt es abzuwägen, wie tief diese Verzeichnisstruktur wirklich sein muss – schließlich sollen es weiterhin möglichst kurze und handliche URLs sein. Ergänzend empfiehlt es sich, über eine Breadcrumb-Navigation sämtliche Eltern der verschiedenen URLs für Crawler und User nachvollziehbar zu verlinken.
Etwas praxisnaher kann ich das an einem Beispiel erklären:
Wenn die Breadcrumb Navigation so aussieht:
Herren » Bekleidung » Hemden » Businesshemden
Dann ist es nicht sinnvoll, allen Ebenen ein eigenes Verzeichnis zu geben, auch wenn es logisch wäre:
example.com/herren/bekleidung/hemden/business-hemden/
Sondern stattdessen das Verzeichnis „Bekleidung“ zu vernachlässigen, weil es sich aus dem Kontext erklärt:
example.com/herren/hemden/business-hemden/
Seitenarchitektur ist natürlich ein Thema für sich – ich behandle es hier nur oberflächlich . Dennoch solltet Ihr hier die Weichen wichtig stellen, bevor Ihr mit irgendwelchen wilden Korrekturen anfangt.
Verlinkt Eure internen Links korrekt
Je größer Eure Seite ist, desto dringlicher werden die Fehler, die Tools wie OnPage.org, DeepCrawl, Audisto & Co. aufzeigen. Zum Beispiel solltet Ihr interne Links auf Weiterleitungen und vor allem daraus resultierende Weiterleitungsketten vermeiden. Auch Links auf Fehlerseiten dürfen Euch nicht passieren, genauso wie Eure Canonicals ohne Umwege auf die korrekten Seiten verweisen sollten. Internen Links solltet Ihr nicht das Attribut rel=nofollow geben.
Eine paar sinnvolle Reports aus OnPage.org sind zum Beispiel diese hier:

All diese Reports mit Hinweisen auf Crawling-Fehler findet ihr in OnPage.org Zoom
Beachtet Eure Klickpfadlänge
Wenn Ihr eine große Seite habt, solltet Ihr auch darauf achten, dass Eure URLs nicht zu weit von der Startseite entfernt sind. Bei OnPage.org heißt dieser Report „Links » Klickpfad“ und sieht zum Beispiel so aus:

Die roten Balken sagen: Liebe Kinder, bitte nicht nachmachen!
Ab einer gewissen Seitengröße kann es durchaus natürlich und im Sinne der Seitenhierarchie sein, dass nicht alle URLs drei Klicks von der Startseite entfernt sind. Daher arbeitet OnPage.org auch mit gelben Balken. Muss der User jedoch siebenmal und öfter klicken, um von der Startseite bis zur endgültigen URL zu kommen, ist das deutlich zu viel. Dann solltet Ihr Euch fragen, ob diese Seiten wichtig sind und ob Ihrsie nicht besser in die Seite integriert (nochmal Stichwort Seitenarchitektur). Sind sie nicht wichtig, dann solltet Ihr Euch überlegen, wieso sie überhaupt noch existieren.
Verwendet eine Sitemap
Bei großen Seiten ist es für Suchmaschinen eine große Hilfe, eine Sitemap zur Orientierung zu haben. 50.000 URLs bzw. 10MB dürfen in eine Sitemap. Wenn Ihr mehr URLs habt, solltet Ihr eine Sitemap-Indexdatei verwenden. Eine solche Sitemap muss allerdings auch gepflegt werden. Wenn reihenweise veraltete URLs in der Sitemap stehen, ist das kontraproduktiv.
Benutzt Parameter
Bei Shopsystemen ist die Verwendung von Parametern zu empfehlen (z.B. example.com/damen-sneaker-beispielmodell?farbe=blau&groesse=38). Durch Parameter können Crawler schon vor dem Crawl interpretieren, welche URLs voneinander abhängig sind, was deren Inhalte sind und wie wichtig sie sind.
Für wichtige Seiten sind aber meistens URLs ohne Parameter die bessere Wahl. In der Search Console (Crawling » URL-Parameter) könnt Ihr Google mitteilen, wofür diese Parameter gedacht sind, wie sich diese auf den Inhalt auswirken und ob sie gecrawlt werden sollten:
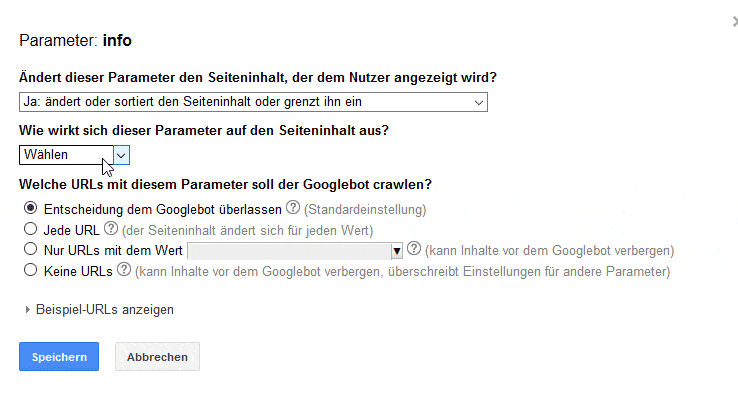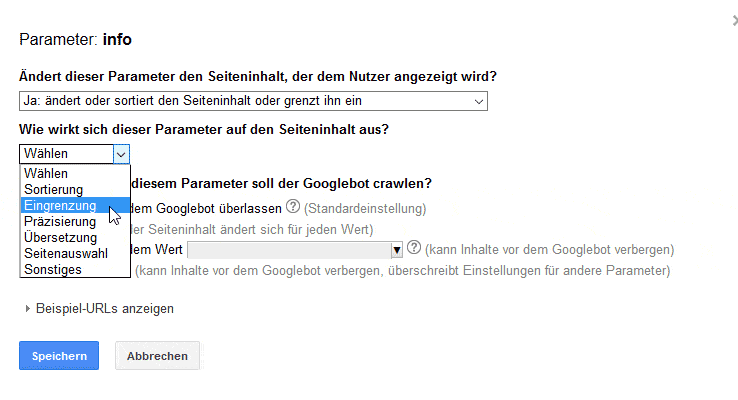
Die Anweisungen, welche URLs Google crawlen soll, sind allerdings irreführend. Eine Analyse der Logfiles zeigt, dass sich darüber nicht das Crawling verbieten lässt. Als Empfehlung an Google ist es trotzdem sinnvoll, die Parameter zu konfigurieren.
Setzt Filter richtig um
Bei Shopsystemen ist die größte Herausforderung meistens der Umgang mit der Filterung. Jeder neue Filter lässt die Anzahl der Shop-URLs exponentiell steigen, wodurch sich der Crawler verrennen kann. Viele Filtermöglichkeiten mit teilbaren URLs sind aber dringend im Sinne des Nutzers und somit auch im Sinne von SEO.
Die falsche Lösung wäre es, die Crawler von diesen Seiteninhalten per robots.txt auszuschließen: Das verstecken von Java Scripts widerspricht inzwischen Googles Richtlinien, und das Verbieten von bestimmten URLs macht diese zu „Schwarzen Löchern“, die eingehende Links wertlos machen.
Stattdessen empfiehlt es sich, mit PRG-Patterns zu arbeiten. Vereinfacht gesagt wird durch den Klick auf die Filterung nur der Inhalt verändert, nicht aber die URL. Danach wird eine URL-Änderung erzwungen, die der Crawler nicht beachtet. Wenn Ihr genauer wissen wollt, wie das funktioniert, empfehle ich Euch die sehr gute Erklärung von Mario Schwertfeger . Der große Vorteil dieser Methode ist, dass die URLs weiterhin existieren, sie werden aber nicht immer und in allen Variationen intern verlinkt.
Verbessert Eure Ladezeiten
Direkt in Zusammenhang mit dem Crawlbudget steht auch die Größe der Seite. Schnell ladende Seiten können auch vom Crawler schneller erfasst werden. Die Ladezeit ist daher besonders für sehr große Seiten ein wichtiger SEO-Hebel. Und mit schicken Seiten wie testmysite.thinkwithgoogle.com macht das sogar noch Spaß! Sehr lohnenswert ist auch ein Blick auf die Dateigrößen und die Wasserfalldiagramme von gtmetrix.com. Für Letzteres könnt Ihr aber auch die Entwicklertools aus Chrome oder Firefox verwenden.
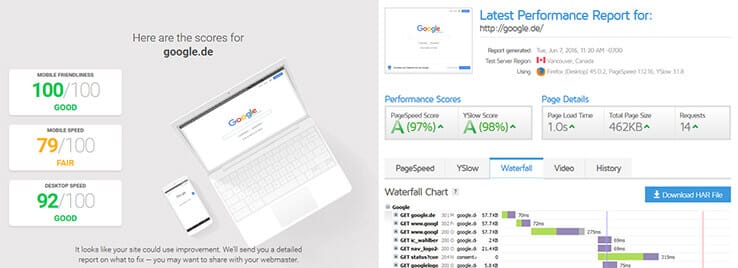
Links seht ihr testmysite, rechts das Wasserfalldiagramm von gtmetrix.com.
Behaltet das ganze Bild im Blick
Letztendlich ist es wichtig, dass Ihr Eure Seite so schlank wie möglich haltet. Die meisten Aufgaben sind schlicht Handwerk, bei denen es kein „vielleicht“, sondern nur „richtig“ und „falsch“ gibt. Natürlich müsst Ihr bei der Umsetzung abwägen, wie viele Ressourcen Ihr dafür verwendet. Aber das Schöne ist: Wenn die Punkte erledigt sind, dann habt Ihr Eure Seite besser gemacht. Google ist glücklich, Ihr seid glücklich – und wenn euch der Artikel geholfen hat, bin auch ich glücklich!
Fehlen wichtige Maßnahmen? Dann lasst es mich in einem Kommentar wissen!
Euch ist das alles zu technisch und Ihr braucht jemanden, der Eure Seite komplett unter die Lupe nimmt und Euch anschließend durch die erforderlichen Maßnahmen führt? Dann stellt Eure SEO-Anfrage.
Bilder: Ameise im Teaserbild © ookawa / istockphoto.com