robots.txt, SEO und Crawling-Steuerung
Die robots.txt Datei dient dazu, Webcrawler anzuweisen, welche Bereiche einer Domain gecrawlt werden sollen und welche nicht. Im Robots Exclusion Standard Protokoll wurde bereits 1994 festgelegt, dass Suchmaschinen-Bots zunächst diese in UTF-8 codierte Textdatei auslesen, bevor sie mit dem Crawling und der Indexierung der betroffenen Domain beginnen. Da es sich bei dem Protokoll um keinen offiziellen Standard handelt, ist nicht gegeben, dass alle (Suchmaschinen-) Crawler die robots.txt wirklich berücksichtigen – Google und Bing sind aber dabei. Heute erkläre ich Dir, wofür Du die robots.txt nutzen kannst, wie sie aufgebaut ist und was es zu beachten gibt.

Du entscheidest, wer Deine Website crawlen darf und wer nicht.
Wofür brauche ich die robots.txt? Syntax & Bedeutung für die Suchmaschinenoptimierung
Mit Hilfe der robots.txt Datei können gewisse Anweisungen für Suchmaschinen-Crawler gegeben werden. Konkret handelt es sich um folgende Funktionen beziehungsweise Datensätze:
- User-agent:
- Allow:
- Disallow:
- Sitemap:
Diese können in Kombination mit Wildcards (Platzhaltern) und Kommentaren genutzt werden. Nachfolgend zeige ich Dir, wie die Syntax einer robots.txt aufgebaut ist und wie Du diese für Deine Website erstellen, bearbeiten und optimieren kannst.
Du solltest Deine robots.txt nur dann bearbeiten, wenn Du Dir sicher bist, was Du hier gerade tust. Andernfalls könntest Du versehentlich Deine gesamte Website, oder Teile davon, für Suchmaschinen unzugänglich machen. Die mögliche Folge: ein starker Ranking- und Traffic-Einbruch.
Wie ist die robots.txt aufgebaut?
Grundsätzlich besteht die robots.txt aus verschiedenen Datensätzen oder Anweisungen. Diese sind immer in zwei Bestandteile aufgeteilt: Zunächst musst Du angeben, für welche Crawler die nachfolgende Anweisung gilt, danach folgt die Anweisung an sich. Crawler werden in diesem Zusammenhang immer als „User-agent“ bezeichnet und die Anweisungen dienen hauptsächlich dazu, dem Crawler etwas zu verbieten („disallow“) oder zu erlauben („allow“). Darüber hinaus kannst Du Deine Sitemap verlinken. Anhand verschiedener Beispiele lässt sich das sehr gut aufzeigen:
Disallow:
# robots.txt zu https://www.meine-domain.de User-agent: Robot-a User-agent: Robot-b Disallow: /fotos/privat/ User-agent: * Disallow: /videos/ Disallow: /party.html
- Die oberste Zeile beginnend mit „#“ ist durch dieses Zeichen auskommentiert und wird nicht gelesen. Sie dient ausschließlich dazu, dass Menschen hier ihre Kommentare einfügen können.
- Im oberen Datensatz werden die fiktiven User-agents „Robot-a“ und „Robot-b“ dazu angewiesen, keine Daten aus dem Verzeichnis /fotos/privat/ sowie dessen Unterverzeichnissen zu crawlen.
- Im unteren Datensatz wird jedem User-agent (à“*“) untersagt, das Verzeichnis /videos/, dessen Unterverzeichnisse sowie das Dokument /party.html zu crawlen.
- Im Umkehrschluss bedeutet das: Alle Crawler – außer „Robot-a“ und „Robot-b“ – dürfen das Verzeichnis /fotos/privat/ inklusive Unterverzeichnissen crawlen und kein Crawler darf /videos/ inklusive Unterverzeichnissen sowie /party.html crawlen.
Warum die robots.txt aus diesem Beispiel nicht dazu geeignet ist, die privaten Fotos, Videos und das HTML-Dokument zur Party zu schützen, erfährst Du weiter unten.
# robots.txt zu https://www.meine-domain.de User-agent: * Disallow: /
Im oberen Beispiel wird jedem Bot alles verboten. Keine Seite darf gecrawlt werden.
# robots.txt zu https://www.meine-domain.de User-agent: * Disallow:
Im oberen Beispiel wird jedem Bot nichts verboten. Alle Seiten dürfen gecrawlt werden.
# robots.txt zu https://www.meine-domain.de User-agent: Robot-a Disallow: User-agent: * Disallow: /
Im oberen Beispiel wir jedem Bot außer „Robot-a“ alles verboten. „Robot-a“ darf alle Seiten der Domain crawlen.
Allow:
Mit der „Allow:“-Funktion kannst Du einzelne Verzeichnisse, Pfade oder Dateien in eigentlich gesperrten Pfaden zum Crawling freigeben. Das macht nur dann Sinn, wenn Du etwas ausdrücklich gesperrt hast.
# robots.txt zu https://www.meine-domain.de User-agent: * Allow: /fotos/oeffentlich/ Disallow: /fotos/
Das Crawling des Verzeichnisses /fotos/oeffentlich/ ist in diesem Beispiel erlaubt, während alle anderen Unterverzeichnisse und Dateien des Verzeichnisses /fotos/ vom Crawling ausgeschlossen sind.
Allow ohne Disallow ist wirkungslos und bringt dir demnach keinerlei Vorteile.
Sitemap:
Neben der Disallow- und der Allow-Funktion gibt es noch die „Sitemap:“- Funktion. Eine XML-Sitemap ist eine Übersicht über alle auf einer Website befindlichen URLs. Mit Hilfe der Funktion „Sitemap:“ kannst Du diese in Deiner robots.txt verlinken. Im Gegensatz zu den anderen Anweisungen ist hier keine Pfadangabe, sondern die gesamte URL der Sitemap erforderlich. Die Sitemap in der robots.txt zu verlinken, kann es Crawlern erleichtern, alle URLs auf Deiner Website zu finden.
# robots.txt zu https://www.meine-domain.de User-agent: * Disallow: Sitemap: https://www.meine-domain.de/sitemap.xml
Die XML-Sitemap in der robots.txt zu verlinken, erachte ich als durchaus sinnvoll – obwohl es möglich ist, die Sitemap in der Google Search Console oder den Bing Webmaster Tools einzureichen und dadurch sicherzustellen, dass sie gefunden und gelesen wird.
Wildcards
Mit Hilfe von Wildcards lassen sich gewisse Ausdrücke in der robots.txt präzisieren und ermöglichen es Dir gleichzeitig, eine Menge Zeit und Arbeit zu sparen. Im Robots Exclusion Protocol sind genau genommen keine regulären Ausdrücke erlaubt, die großen Suchmaschinen-Crawler unterstützen aber die folgenden zwei Wildcards. Deren Verwendung ist vor allem aufgrund der beschränkten Anzahl auch für „Regex-Anfänger“ schnell einleuchtend:
- „*“ bedeutet, dass irgendein Zeichen beliebig oft wiederholt werden kann.
- „$“ bedeutet, dass hier das Zeilenende ist.
# robots.txt zu https://www.meine-domain.de User-agent: * Disallow: /fotos*/
Im oberen Beispiel werden alle Unterseiten ausgeschlossen, die mit „fotos“ beginnen, etwa „/fotos-von-der-party/“.
# robots.txt zu https://www.meine-domain.de User-agent: * Disallow: /*fotos/
Im oberen Beispiel werden alle Unterseiten ausgeschlossen, die mit „fotos“ enden, etwa „urlaubsfotos“.
# robots.txt zu https://www.meine-domain.de User-agent: * Disallow: /*fotos*/
Im oberen Beispiel werden alle Unterseiten ausgeschlossen, die „fotos“ enthalten.
# robots.txt zu https://www.meine-domain.de User-agent: * Disallow: /*.jpeg$
Im oberen Beispiel werden alle Dateien ausgeschlossen, die auf „.jpeg“ enden.
Der große Vorteil der Wildcards in einer robots.txt besteht darin, dass Du nicht jeden einzelnen Pfad oder jede einzelne Datei aufführen musst, sondern mit Platzhaltern arbeiten kannst.
Wo ist die robots.txt gespeichert?
Die robots.txt muss unter genau dieser Bezeichnung im Root-Ordner (also im Hauptverzeichnis) Deiner Domain abgelegt sein. Angenommen Deine Domain lautet „meine-domain.de“, dann muss die robots.txt unter dieser Adresse aufrufbar sein: https://www.meine-domain.de/robots.txt.
Was ist, wenn ich keine robots.txt habe?
Wenn Du keine oder eine leere robots.txt auf Deiner Website hast, ist das erstmal kein Problem. Das ist insbesondere dann der Fall, wenn Du die XML-Sitemap in der Search Console eingereicht und nicht gerade 100.000 URLs samt Filter-URLs hast.
Tipp: Sieh dir mal die robots.txt von seokratie.de an!
Wie ändere ich die robots.txt auf meiner Website?
Einige CMS bieten Dir per default die Möglichkeit, Deine robots.txt im Backend anzupassen, bei anderen ist ein Plugin erforderlich. WordPress beispielsweise erlaubt es Dir standardmäßig nicht, direkt im Backend Änderungen an der Datei vorzunehmen – es sei denn, Du hast ein SEO-Plugin installiert (was ich Dir grundsätzlich empfehle).
robots.txt mit dem Yoast SEO Plugin ändern
Im Yoast SEO Plugin kannst Du unter Werkzeuge > Datei-Editor neben der .htaccess auch die robots.txt bearbeiten:

Werkezeuge im Yoast SEO Plugin
Wie Du siehst, kannst Du hier beliebigen Text einfügen.
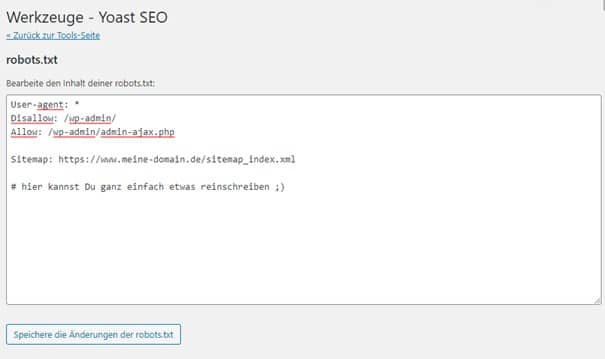
robots.txt im Yoast SEO Plugin ändern
Sobald Du Deine Änderungen gespeichert hast, ist die neue Version live.
robots.txt über FTP-Upload ändern
Diese Möglichkeit geht eigentlich immer – CMS-unabhängig. Mit einem FTP-Client wie etwa FileZilla kannst Du, nach Eingabe von
- Server,
- Benutzername,
- Passwort und
- Port,
eine Verbindung zu Deiner Website herstellen und hier auf alle Dateien zugreifen. Falls im Root-Ordner noch keine robots.txt existiert, kannst Du diese mit Hilfe eines simplen Text-Editors erstellen. Wichtig ist, wie gesagt, dass Du sie unter dem richtigen Dateinamen abspeicherst:

robots.txt im Windows-Editor erstellen
Nun kannst Du diese Datei über den FTP-Upload im richtigen Verzeichnis speichern.
robots.txt überprüfen
Letztendlich kannst Du mit Hilfe des in der Google Search Console eingebauten robots.txt-Testers prüfen, ob und welche URLs für die verschiedenen Googlebots aufrufbar sind und welche nicht. In der neuen Version der Search Console gibt es die Funktion (noch) nicht. Du musst daher auf die alte Version zurückgreifen.

robots.txt-Tester in der alten Google Search Console
Auch der Screaming Frog SEO Spider bietet einige Möglichkeiten zur Validierung einer robots.txt – auch in einer Testumgebung. Es bietet sich an, zunächst einen normalen Crawl unter Berücksichtigung der robots.txt durchzuführen und anschließend noch einen Crawl, bei dem die Datei ignoriert und der Status berichtet wird. Unter Configuration > robots.txt > Settings gelangst Du zu den hierfür relevanten Einstellungen:
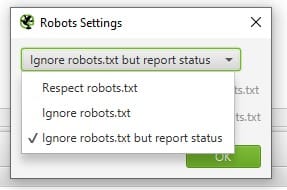
Einstellungsmöglichkeiten zur robots.txt in Screaming Frog SEO Spider
Kann ich noindex in der robots.txt verwenden?
Nein. Google unterstützt weder noindex, noch nofollow oder crawl-delay in der robots.txt. Das hat der Suchmaschinen-Riese 2019 in einem Blogbeitrag klargestellt. Es gibt aber andere Möglichkeiten, mit denen Du kontrollieren kannst, welche Teile Deiner Website gecrawlt und indexiert werden:
- noindex im robots meta Tag
- Die Seite kann so zwar gecrawlt werden, sie wird aber nicht indexiert und kann somit nicht in den SERPs erscheinen
- Statuscode 404 oder 410 setzen
- Beide Statuscodes bedeuten, dass die angeforderte Ressource nicht (mehr) verfügbar ist. Folglich werden derartige URLs, nachdem sie gecrawlt wurden, aus dem Google Index entfernt.
- Passwortschutz
- Durch ein Passwort geschützte Seiten sind für Crawler unzugänglich und können nicht gecrawlt und indexiert werden.
- Entfernen-Tool in der Search Console
- Mit diesem recht neuen Tool kannst Du in der Search Console unter Index > Entfernen Seiten einreichen, die Du (temporär) nicht mehr in den SERPS vorfinden möchtest.
Wenn Du Deine oben angesprochenen privaten Fotos, Videos und das HTML-Dokument zur Party schützen möchtest, empfiehlt es sich, einen Passwortschutz zu hinterlegen. Das ist die mit Abstand beste Möglichkeit, um ungewollte Zugriffe zu vermeiden.
Was sind mögliche Probleme mit der robots.txt?
Meiner Meinung kann das größte Problem Deiner robots.txt Datei dadurch entstehen, dass Du aus Versehen einen Teil oder sogar Deine gesamte Website vom Crawling ausschließt. Abhilfe können dir hier eventuell Tools bringen, die Dich bei Änderungen Deiner robots.txt sofort benachrichtigen.
Sofern Du sensible Seiten per disallow-Befehl für Suchmaschinen-Crawler ausgeschlossen hast, könnten bösartige Crawler das für sich nutzen und genau hier ansetzen.
Ansonsten können widersprüchliche Pfadangaben sowie ein fehlerhafter Aufbau (etwa zu viele Leerzeichen) zu Problemen führen.
Sollte ich überhaupt eine Robots.txt verwenden?
Diese Frage lässt sich nicht pauschal beantworten, da es sehr stark davon abhängig ist, was für eine Art von Website Du hast. Grundsätzlich ist bei einem simplen Blog nichts dagegen einzuwenden, eine robots.txt mit der Erlaubnis für alle Crawler, alles zu crawlen sowie einem Verweis auf die XML-Sitemap, zu haben. Das würde, wie gesagt, so aussehen:
# robots.txt zu https://www.meine-domain.de User-agent: * Disallow: Sitemap: https://www.meine-domain.de/sitemap.xml
Aber dafür ist auch nichts einzuwenden. Du kannst dir die Mühe also auch sparen ;).
Der sinnvolle Inhalt Deiner Robots.txt ist ansonsten sehr stark vom CMS und den Features auf Deiner Website abhängig. Oftmals ausgeschlossen werden beispielsweise:
- Der Check-out-Prozess
- Die Dankesseiten
- Bereiche, die nur für eingeloggte User sichtbar sind
- Suchergebnisseiten der internen Suche
- Tag-Seiten
- Seiten zu verschiedenen Filteroptionen, um Duplicate Content zu vermeiden
- Seiten, die durch „zur Wunschliste hinzufügen“ generiert werden.
Grundsätzlich würde ich Dir in keinem der obengenannten Fälle dazu raten, dass Du mittels robots.txt den Inhalt sperrst. Zwar sind diese Inhalte auf den ersten Blick nicht relevant für den Googlebot – aber oftmals notwendig, damit Google versteht, worum es bei Deiner Website geht. Per robots.txt würde ich nur dann Seiten aussperren, wenn Du massive Probleme mit dem Crawling hast und der Googlebot zu viel crawlt. Wenn Du URLs nicht indexieren möchtest, dann benutze am besten die Funktion noindex im robots meta Tag.
Benutzt Du auf Deiner Website eine robots.txt? Was für eine Art von Website hast Du? Hast Du hier etwas ausgeschlossen? Ich freue mich auf Deinen Input in den Kommentaren!
Titelbild: Victor_Brave/ Gettyimages.de




