Logfile-Analyse: So wertest Du aus, was Google crawlt
Welche Seiten besucht Google eigentlich auf Deiner Website? Und wie häufig? Diese Fragen lassen sich mit SEO-Tools und selbst mit der Google Search Console nicht vollständig beantworten. Um das herauszufinden, musst Du Dich durch Deine Logfiles graben.

Logfiles sind erst einmal viel unlesbarer Text, dann aber eine Welt voller SEO-Input.
Warum solltest Du Logfiles auswerten?
Google verwendet Crawler, um alle Websites der Welt zu erschließen und indexieren zu können. Das ist sehr aufwendig und kostet viele Ressourcen. Daher gibt es für jede Domain ein individuelles Crawlbudget. Wenn bei diesen gecrawlten Seiten dann sehr viele unwichtige, minderwertige oder sogar fehlerhafte Seiten dabei sind, ist das kein gutes Signal. Noch dazu werden dann Deine guten und wichtigen Seiten seltener besucht.
In der Search Console kannst Du zwar sehen, wie viele URLs Google gecrawlt hat. Welche genau, das kannst Du allerdings nicht sehen. Du siehst zwar einen Teil über den neuen Abdeckungs-Report, aber nicht alles. Wenn Du wirklich wissen willst, wie gesund Deine Seite ist, musst Du Deine Logfiles auswerten.
Was ist überhaupt ein Logfile?
Logfiles sind Dateien, die automatisch auf dem Server einer Website gespeichert werden. In den Access Logs siehst Du jeden Hit, also jede Anfrage an den Server, auch die des Googlebots. Je nach Anzahl der Seitenaufrufe kann so eine Datei dadurch ziemlich groß sein. Logfiles werden daher auch oft bereits nach wenigen Wochen automatisch wieder gelöscht. Es gilt also, rechtzeitig oder regelmäßig die Daten herunterzuladen oder zu sichern.

Eine Log-Datei enthält aneinandergereiht jede Menge identisch aufgebauter Zeilen. Jede Zeile entspricht einem Aufruf und enthält in der Regel diese Informationen:
- IP des Aufrufenden
- Zeitpunkt des Aufrufs
- URI, also den Pfad der aufgerufenen Seite
- Protokoll
- Status Code, also die Antwort des Servers
- Übertragene Bytes
- User Agent
So eine Zeile sieht dann zum Beispiel so aus:
66.249.123.456 – – [28/Nov/2018:03:53:40 +0200] „GET /logfile-analyse HTTP/1.0“ 200 25518 „-“ „Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)“
Dadurch, dass die IP in Logfiles gespeichert wird, sind Logfiles auch datenschutzrechtlich relevant. Damit in Sachen DSGVO alles sichergestellt ist, sollte die IP in den Logfiles daher anonymisiert werden. Das lässt sich zum Beispiel umsetzen, indem der letzte Zeichenblock mit einem Skript durch eine 0 ersetzt wird.
Wie sehe ich, was Google auf meiner Seite crawlt?
Über den User Agent, der bei jedem Aufruf mitgeliefert wird, lässt sich der Googlebot identifizieren. So heißt der typische Googlebot „Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)“. Seit dem Mobile Index crawlt der „Googlebot Smartphone“ noch häufiger. Allerdings kann jeder, wenn er möchte, mit diesem User Agent crawlen. Dadurch muss nicht jeder User Agent „Googlebot“ auch tatsächlich der Crawler von Google sein. Dadurch ist es nicht sinnvoll, sich allein auf den User Agent zu verlassen.
Wie kann ich den Googlebot verifizieren?
Google crawlt in der Regel von IPs aus, die mit 66.249. beginnen. Anhand dieser IP Range lässt sich der Zugriff als echter Googlebot verifizieren. Um ganz sicherzugehen, kannst Du die täglichen Googlebot-Zugriffe mit den offiziellen Zahlen aus der Google Search Console vergleichen (in der alten Search Console unter Crawling > Crawling-Statistiken).
Wie kann ich die Logfiles auswerten?
Jetzt könntest Du natürlich anfangen, die riesigen Dateien zu entpacken, die einzelnen Elemente als Spalten in Excel aufzubereiten und die entsprechenden Googlebot-Zeilen herauszufiltern. Kann man machen, wird aber schnell frustrierend. Daher haben findige Leute Tools entwickelt.
Wir verwenden den Screaming Frog Log File Analyser. Dort können wir die komprimierten Logfiles einfach per Drag & Drop einfügen und das Tool filtert selbstständig alle Suchmaschinen-Bots heraus. Das sieht dann in etwa so aus:
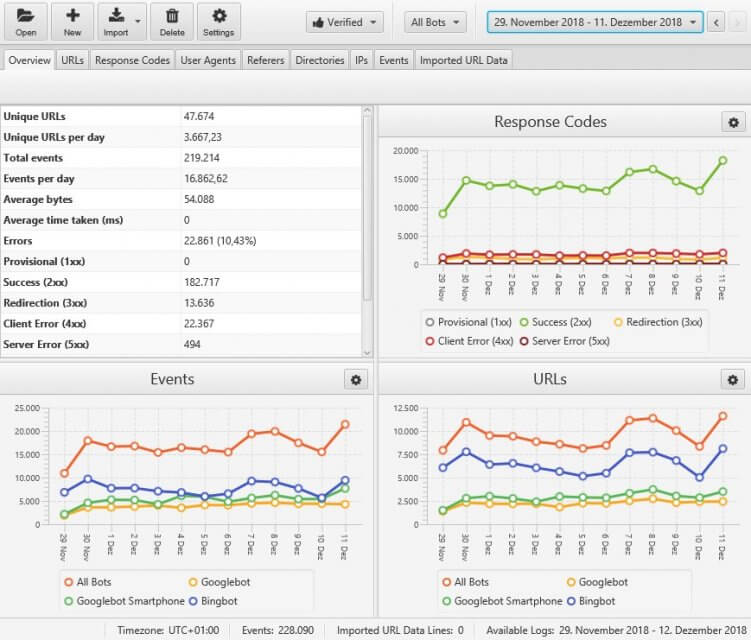
Es gibt aber auch diverse andere Tools. Um laufend die Logfiles zu verarbeiten und auszuwerten, ist eine beliebte Lösung das sogenannte ELK-Stack, bestehend aus den Open-Source-Lösungen Elasticsearch, Logstash und Kibana.
Wie bringt mir das in der Praxis?
Die Theorie hinter Logfiles ist ja schön und gut, aber die eigentliche Frage ist ja: Welche Schlüsse und Maßnahmen kannst Du aus den vielen Daten ableiten? Die folgenden zwei Beispiele machen das Thema hoffentlich etwas greifbarer.
Beispiel 1: Unliebsame Parameter
Eine Logfile-Analyse hat uns bei einem unserer Kunden gezeigt, dass Google enorm viele URLs mit Parametern crawlte. Als simple Maßnahme haben wir in der Parameterbehandlung angegeben, dass Google keine URLs crawlen soll:
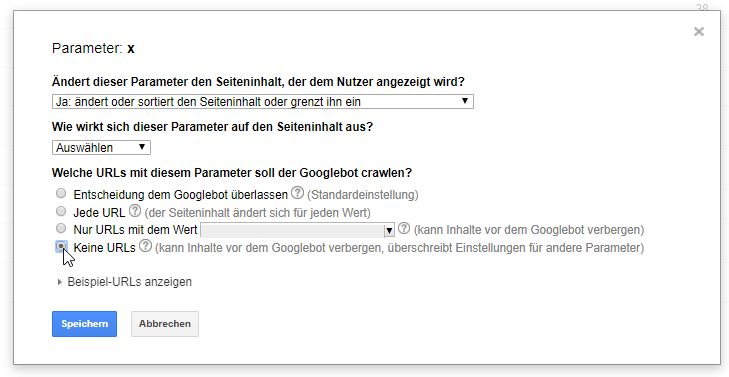
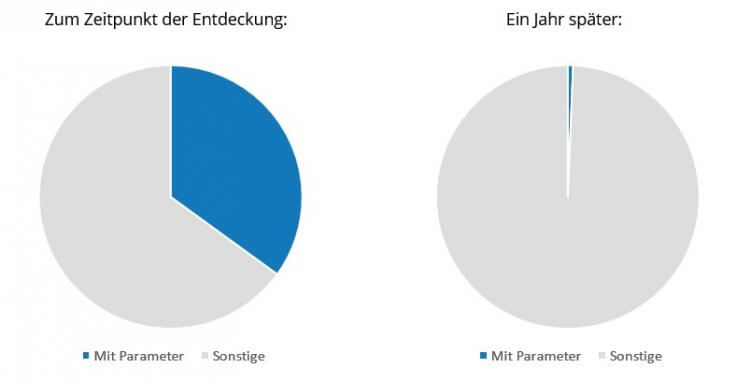
Das Ergebnis konnten wir in den Logfiles sehen: Ein Jahr später crawlte Google nur noch eine Handvoll der ungewollten Parameter-URLs:
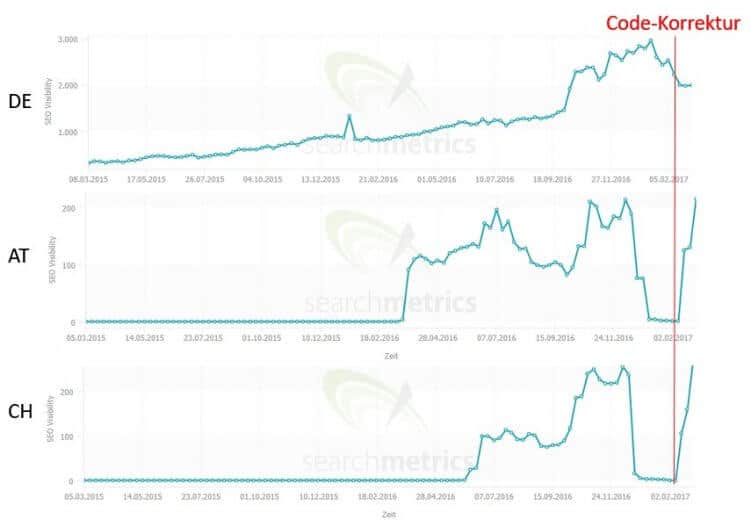
Beispiel 2: Fehlerhafte Canonicals
Nach einem Ranking-Absturz in zwei Ländern konnten wir bei einem anderen Kunden in unseren Crawls und auf den wichtigen Landingpages keine Fehler entdecken. Also haben wir uns die Logfiles angesehen. Dort haben wir gesehen, dass der Großteil der gecrawlten URLs einen Parameter enthielt:

1563 von 168 gecrawlten URLs enthielten einen Parameter – obwohl eigentlich keine existieren sollten.
All diese Parameter-URLs waren ungewollte Seiten. Es stellte sich heraus, dass die Canonicals dieser Seiten auf sich selbst verwiesen, obwohl es sich um Duplicate Content handelte und sie auf die Seite ohne Parameter hätten verweisen müssen. Weil die von Google gecrawlten Seiten nicht verlinkt waren, konnten keine SEO-Tools die fehlerhaften, doppelten Seiten finden. Als Konsequenz haben wir aus den Canonicals die Parameter entfernt und die Rankings waren wieder da:
Wie kann ich aus Logfiles Maßnahmen ableiten?
Anfangs stehen viele aufgrund der Masse an Daten wie der Ochs vorm Berg. Daher habe ich ein paar Ansätze für Dich, was Maßnahmen aus den Erkenntnissen aus Deinen Logfiles sein können:
- Seitenarten: Werden Seitenarten oder Seitenregionen gecrawlt, die eigentlich unwichtig sind? Dann solltest Du diese in der robots.txt sperren und die Links dorthin entfernen. Falls die Links nötig sind, solltest Du sie über PRG-Pattern oder „nofollow“ für Google nicht verfolgbar machen.
- Status Codes:
- Crawlt Google viele 404-Seiten häufiger? Waren diese früher einmal relevant, ist es womöglich sinnvoll, diese weiterzuleiten.
- Crawlt Google bestimmte 301-Weiterleitungen häufig? Falls diese noch intern verlinkt werden, solltest Du diese Links korrigieren.
- Statische URLs: Werden statische Ressourcen wie Schriften und Skripte sehr häufig (hunderte Male am Tag) gecrawlt? Dann solltest Du womöglich deren Http-Header anders konfigurieren.
- Beim Relaunch: Werden nach dem Relaunch URLs gecrawlt, die bisher nicht gecrawlt wurden? Falls ja, solltest Du prüfen, ob diese URLs absichtlich entstanden sind.
- Bei vielen Produkten: Werden alle Produkte gecrawlt? Falls einige nicht gecrawlt werden, solltest Du nach Gemeinsamkeiten schauen und diese besser intern verlinken.
Wann solltest Du Logfiles nutzen?
Die Logfiles geben ein sehr ehrliches Bild über die Gesundheit der Seite ab. Gerade bei sehr großen Seiten, bei denen Crawlingsteuerung besonders wichtig ist, ist die Analyse der Logfiles enorm wichtig. Bei kleineren Seiten und Seiten, bei denen es noch viele offensichtliche Baustellen gibt, ist ein Blick in die Logfiles meist in einem späteren Schritt sinnvoller. Dann lohnt sich aber ein regelmäßiger Blick darauf – zumindest aber nach größeren Veränderungen.
Wie nutzt Du die Logfiles? Und welche Maßnahmen leitest Du daraus ab? Schreibe es gern in die Kommentare!





