Gecrawlt/gefunden, zurzeit nicht indexiert – und nun?
„Gecrawlt – zurzeit nicht indexiert“ und „Gefunden – zurzeit nicht indexiert“ – was bedeuten diese beiden Berichte in der Google Search Console? Diese Frage erreicht uns oft über die unterschiedlichsten Kanäle. Warum Google bestimmte URLs nicht indexiert und in welchen Fällen das Deiner SEO-Performance schadet, verrate ich Dir in diesem Blogpost.

Was tun, wenn Google viele URLs crawlt, aber (zurzeit) nicht indexiert?
Inhalt
Die Basis: Wie werden URLs indexiert?
Um zu verstehen, warum Seiten nicht indexiert werden, solltest Du wissen, welche Schritte überhaupt notwendig sind, bevor eine URL im Index landet – also in den Suchmaschinenergebnissen (SERPs) gelistet wird.
Der Suchmaschinen-Bot folgt beim Crawling den Verlinkungen – er arbeitet sich von Link zu Link vor. Entdeckt er dabei eine neue URL, dann passiert Folgendes: Der Bot crawlt die Seite (das passiert nicht immer sofort!), das heißt er lädt sie herunter und erfasst die Inhalte. Dann bewertet Google den Inhalt hinsichtlich der Relevanz für bestimmte Suchanfragen. Im besten Fall lautet das Urteil danach: „Super, diese URL ist relevant und nützlich für den Nutzer, ich indexiere sie sofort.“
Um den aktuellen Indexierungsstatus Deiner Seiten zu prüfen, lohnt sich ein Blick die neue Screaming Google Search Console API-Funktion: Hier siehst Du pro Seite sehr übersichtlich, welche URLs im Google Index sind und welche URLs von Google ausgeschlossen werden:

Im Tab „Search Console“ des Screaming Frog Crawls kannst Du unter anderem nach Abdeckung filtern.
Was bedeutet „Gecrawlt – zurzeit nicht indexiert“?
Es kommt vor, dass Google URLs zwar crawlt, aber nicht sofort indexiert. In dem Fall tauchen diese im Abdeckungsbericht der Google Search Console auf mit dem Hinweis:
„Die Seite wurde von Google gecrawlt, aber nicht indexiert. Sie könnte jedoch in Zukunft indexiert werden. Sie brauchen diese URL nicht noch einmal zum Crawling einzureichen.“
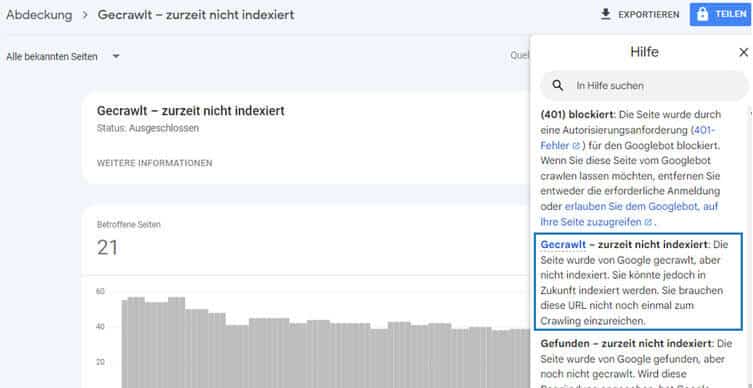
Erklärungen zur den einzelnen Abdeckungsbereichen findest Du im Hilfebereich der Google Search Console.
Warum werden URLs gecrawlt, aber nicht indexiert?
Warum lädt und rendert der Suchmaschinenbot manche URLs, indexiert sie aber nicht (sofort)? Das kann verschiedene Ursachen haben.
Du hast keine Zeit zum Lesen? Dann schau Dir den SEO-Quick-Tipp zum Thema von meiner SEO-Kollegin Nora an:
Auch Google braucht ein bisschen Zeit
Ein simpler Grund: Google und andere Suchmaschinen haben begrenzte Ressourcen und können nicht alle URLs simultan bewerten und indexieren. Es ist also normal, dass es eine Weile dauern kann, bis Deine Seiten im Index auftauchen. Überprüfe am besten in regelmäßigen Abständen den Indexierungsstatus von neuen wichtigen Inhalten.
Qualität & Relevanz der Contents
Googles Maxime ist es, nur Seiten zu indexieren, die für bestimmte Suchanfragen eines Nutzers relevant und nützlich sind. Erfüllen Inhalte diese Ansprüche nicht, werden sie nach dem Crawling auch nicht indexiert.
Dazu zählen:
1. Duplicate Content
Doppelte Inhalte mag Google nicht sonderlich. Zum einen, weil mehr Ressourcen benötigt werden, um mehrere identische Inhalte zu crawlen. Zum anderen muss Google auch bewerten: Welche URL ist für die Suchanfrage die relevanteste? Je mehr ähnliche Seiten es gibt, desto komplexer ist dieses Vorhaben. Im Zweifel wird sich Google die Zeit und Ressourcen sparen und die Seite im schlechtesten Fall nicht einmal mehr crawlen.
2. Thin Content
Sind auf einer Seite nur ein Video ohne Metadaten und eine Textzeile eingebunden – und fehlt auch noch die H1-Überschrift – dann wird Google die URL sehr wahrscheinlich als „dünnen“ Inhalt einstufen. Dasselbe gilt für eine Bilderstrecke ohne Bildunterschriften. Aus einem einfachen Grund: Google benötigt auslesbaren Text, um Seiteninhalte bewerten zu können.

Diese Video-SEO-Checkliste meiner Kollegin Christina gibt Dir einen guten ersten Überblick, was Du bei Video-Landingpages beachten solltest.
Ein anderes Beispiel: Du hast (nicht nur temporär) eine Produktkategorieseite mit nur einem einzigen Produkt: Das ist dann ein dünner Inhalt. Vor allem, wenn Mitbewerber in der gleichen Rubrik 50 Produkte anbieten.
Achtung: Es geht nicht darum, möglichst viel Text auf jede Seite zu stellen. Wichtig ist, dass die Suchintention des Nutzers für eine bestimmte Anfrage erfüllt ist und Du Google via Metadaten und optimierter H-Auszeichnung genügend Input gibst, worum es auf dieser Seite geht.
3. Schlechte interne Verlinkung
Ein weiterer Grund für den Status „Gecrawlt – zurzeit nicht indexiert“ ist eine schlechte interne Verlinkung. Findet Google eine URL erst versteckt in der 12. Verzeichnisebene oder nur über die Sitemap, dann wird der Bot zu Recht annehmen: Dieser Inhalt scheint nicht relevant zu sein. Der Nutzer wird diesen Inhalt ohnehin nicht finden – oder nur per Zufall.
Wie Du die interne Verlinkung Deiner Seite optimierst, erklärt Dir meine SEO-Kollegin Anika in ihrem Blogpost.
4. Inhalte, die nicht mehr aktuell sind
Ein alter Inhalt muss nicht automatisch ein schlechter Inhalt sein. Aber: Alt und irrelevant ist eine Kombination, die wahrscheinlich nicht in den SERPS auftauchen wird. Ein Blogpost zu Lippenstifttrends 2014 wird im Jahr 2022 keinen Menschen mehr interessieren. Dasselbe Schicksal teilen zum Beispiel auch Produkte aus der VorVorVorsaison, die längst nicht mehr verfügbar sind.
Aus „alt und irrelevant“ kannst Du in einigen Fällen „aktuell und relevant“ machen: Mein Content Marketing Kollege Martin Stäbe zeigt Dir in seinem Blogpost, wie Du dabei vorgehst: Content Repurposing-Ideen
Was tun?
Jetzt weißt Du, warum URLs im Abdeckungsbericht „Gecrawlt – zurzeit nicht indexiert“ landen. Die Gretchen-Frage heißt jedoch nicht „Was soll ich tun?“ , sondern: „Muss ich überhaupt etwas tun?“
Wichtig: Je größer Deine Domain ist, desto eher wirst Du nicht indexierte URLs in Deinem Abdeckungsbericht finden. Das ist völlig normal und nicht immer ein Grund zu Handeln. Dein Ziel ist nicht die 100prozentige Indexierung. Dein Ziel ist es, dass
- Deine wichtigen Seiten indexiert werden.
- Dein Crawlbudget effizient genutzt wird und Google möglichst wenig unwichtige URLs crawlt.

Welche Möglichkeiten gibt, um Crawling und Indexierung zu steuern? Hier empfehle ich Dir, die Dokumentation bei Google Search Central zum Thema Crawling- und Indexierungssteuerung zu lesen.
Du solltest zuerst sicherstellen, dass keine Deiner wichtigen Seiten im Abdeckungsbericht „Gecrawlt – derzeit nicht indexiert“ auftaucht. Durch kontinuierliches SEO-Monitoring hast Du im besten Fall die Top-Inhalte Deiner Domain immer im Blick.
Im nächsten Schritt geht es darum: Wie viele URLs sind es überhaupt, die Google nicht indexieren mag? Diese Anzahl solltest Du immer in Relation zur Gesamtanzahl der Seiten betrachten.
Ein Beispiel: Hat Deine Domain nur 150 Seiten, dann sind 50 nicht-indexierte URLs durchaus relevant, bei einer Domain mit 50.000 URLs sind 50 Seiten aber sehr wenig.
Außerdem wichtig:
- Wie ist die Tendenz?
- Wächst die Anzahl der gecrawlten, nicht indexierten Seiten an?
Ein sprunghafter Anstieg nicht-indexierter Seiten kann darauf hindeuten, dass zu einem bestimmten Zeitpunkt viele URLs mit ähnlichen Inhalten erstellt wurden.
Ein Beispiel: Du hast eine neue Produktkategorie erstellt und vergessen, den dabei neu entstehenden Filter-URLs eine Sonderbehandlung angedeihen zu lassen wie zum Beispiel den Ausschluss über die robots.txt. Welche weiteren Arten es gibt, mit Filter-URLs umzugehen, liest Du in diesem Blogpost: Facettensuche und SEO
Bei dieser großen Domain (>50.000 URLs) gab es ca. 10.000 URLs, die nach dem Crawling nicht indexiert wurden. Ein großer Anteil davon waren inhaltlich identische Parameter-URLS – und damit Duplicate Content. Nach Ausschluss in der robots.txt geht die Anzahl deutlich zurück:

Ergebnis: Es sind nur noch 3.000 URLs übrig.
Da Du nicht alle URLs manuell durchgehen kannst und sollst, suche nach Mustern:
Was haben die nicht indexierten Inhalte gemeinsam und auf welche Ursache weist dies hin?
Haben die URLs zum Beispiel immer denselben Aufbau und einen bestimmten Parameter, weist das auf Duplicate Content hin.
Gehören viele Inhalte derselben Seitenart an – also zum Beispiel Video-Beiträge, Produktkategorien oder bestimmte Produktdetailseiten, solltest Du Dir die Qualität der Inhalte hinsichtlich Thin Content anschauen.
Ursache(n) gefunden? Dann hast Du den wichtigsten Teil erledigt. Deine Maßnahmen kannst Du jetzt gezielt ausrichten: Inhalte löschen, zusammenfassen, optimieren, URLs vom Crawling ausschließen oder die interne Verlinkung anpassen.
Was bedeutet „Gefunden – zurzeit nicht indexiert“?
Ein zweiter sehr ähnlicher Bericht in der Google Search Console lautet „Gefunden – zurzeit nicht indexiert“. Diese Seiten hat Google gesehen, aber nicht gecrawlt – also nicht heruntergeladen und gerendert. Google selbst gibt als Grund hierfür ein technisches Problem an:
„Wird diese Begründung angegeben, hat Google normalerweise versucht die URL zu crawlen, aber das hätte die Website überlastet. Daher hat Google das Crawling neu geplant, aus diesem Grund ist das Feld mit dem letzten Crawling-Datum im Bericht leer.“
Jetzt solltest Du im ersten Schritt ausschließen, dass Deine Seitenperformance wirklich die Ursache ist. Worauf Du dabei achten musst, erklärt Dir meine SEO-Kollegin Nora in diesem Quick-Tipp:
Eine schlechte Seitenperformance ist jedoch nur ein Grund. Laut Google Webmaster Trend Analyst John Mueller spielen (ähnlich wie beim Bericht „Gecrawlt – zurzeit nicht indexiert“) Qualität und Relevanz eine zentrale Rolle.
Findest Du einen großen Anteil Deiner Seiten unter „Gefunden – zurzeit nicht indexiert“ solltest Du neben der internen Verlinkung vor allem prüfen: Entstehen viele ähnlich aufgebaute URLs (zum Beispiel durch automatisiert erstellte Inhalte)? Laut Mueller entscheidet Google in diesem Fall oft, dass es sich nicht lohnt, diese vielen Seiten zu crawlen. Weil sie nicht hilfreich und relevant für den Nutzer sind.
Was zu tun ist? Hier gehst Du grundsätzlich genauso vor, wie bei den gecrawlten, nicht indexierten URLs: Finde im ersten Schritt heraus, ob Handlungsbedarf besteht, weil viele URLs oder sehr wichtige Inhalte in „Gefunden – zurzeit nicht indexiert“ sind. Wenn ja, richten sich Deine Maßnahmen nach der Ursache: Optimiere Deine interne Verlinkung und stelle sicher, dass kein crawlbarer Duplicate Content entsteht.

Circa 400 nicht gecrawlte URLs auf einer Domain mit über 20.000 Seiten: Hier reicht eine grobe Überprüfung aus.
Fazit
Nicht jede einzelne URL Deiner Domain muss indexiert sein. Wichtig ist, dass jede Deiner relevanten Seiten im Google-Index ist und die Anzahl der gecrawlten unwichtigen URLs so gering wie möglich bleibt. Das gilt insbesondere für große Webseiten. Hast Du einen hohen Anteil nicht indexierter Seiten im Verhältnis zu den indexierten, dann solltest Du auf jeden Fall in die Analyse gehen. Bei dieser Einschätzung helfen Dir die beiden Berichte „Gecrawlt – zurzeit nicht indexiert“ und „Gefunden – zurzeit nicht indexiert“.
Findest Du hier sehr viele irrelevante URLs, solltest Du prüfen, ob Du ihre Entstehung technisch vermeiden kannst oder sie via robots.txt ausschließen.
Landen für Dich wichtige Seiten in diesen beiden Berichten, richten sich Deine Maßnahmen nach der Ursache.
Das bedeutet:
- Prüfe, ob Du ein Duplicate Content-Problem hast – und behebe es.
- Stelle sicher, dass Du einzigartige und aktuelle Inhalte veröffentlichst, die einen spezifischen Suchintent des Nutzers erfüllen und sich dies im Keywordfokus widerspiegelt.
- Optimiere die interne Verlinkung, so dass der Bot Deine Seiten auf kurzem Weg erreichen kann.
- Stelle sicher, dass die Seiten in der Sitemap gesendet werden.
Welche Erfolgs- oder Nicht-Erfolgserlebnisse hast Du mit nicht-indexierten URLs im Abdeckungsbericht gemacht? Schreib mir gern in den Kommentaren Deine Erfahrungen.
Bilder: Adobe Stock & Screenshots / Titelbild: volurol, Bild 1: Screenshot, Bild 2: Screenshot. Bild 3: Knut, Bild 4:DigiClack, Bild 5: Screenshot, Bild 6: Screenshot





