User-Agent einfach erklärt
Der User-Agent ist ein HTTP-Header, den Dein Browser beim Aufruf einer URL an den Server schickt. Mit dem User-Agent erfährt die Website Deinen Browser (z. B. Google Chrome) und Dein Betriebssystem (z. B. Windows 10). Crawler wie der Googlebot oder Geräte wie Spielkonsolen identifizieren sich auch per User-Agent.
Beispiel:
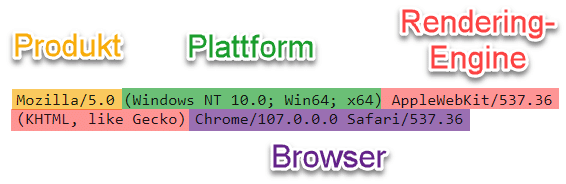
Der User-Agent besteht aus 4 Teilen:
- Produkt: ist aus historischen Gründen fast immer „Mozilla/5.0“. Sagt aus, dass der User-Agent zu Mozilla kompatibel ist.
- Plattform: Betriebssystem, Version und Architektur (32 Bit vs. 64 Bit)
- Rendering-Engine: System, mit dem der Browser aus HTML, Bildern, CSS & JavaScript die optisch sichtbare Website zusammenbaut
- Browser: Browser-Name und -Version. Enthält oft zusätzlich andere Browser-Namen, zu denen der Browser kompatibel ist.
Manche Browser fügen dem User-Agent zusätzliche Informationen hinzu oder verändern die Reihenfolge der Angaben. Die Kernangaben zu Browser und Betriebssystem werden aber praktisch immer angegeben.
Inhalt
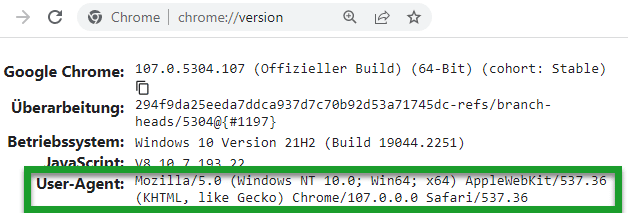
Wo finde ich meinen User-Agent?
Nutzt Du den Google Chrome, musst Du chrome://version in die Adressleiste eingeben:
Rufe alternativ http://wieistmeinuseragent.de/ auf. Die Website zeigt Dir dann Deinen User-Agent:

Was ist ein User-Agent-Switcher?
Mit einem User-Agent-Switcher kannst Du einer Website vortäuschen, dass Du einen anderen Browser oder ein anderes Betriebssystem nutzt, indem Du den User-Agent änderst. So kannst Du prüfen, ob sich Deine Website je nach User-Agent anders verhält, z. B. andere Inhalte ausliefert. Das kann bei der Website-Entwicklung hilfreich sein.
Aus Nutzersicht kann ein User-Agent-Switcher für mehr Datenschutz sorgen, weil die Website nicht mehr Dein wahres Betriebssystem bzw. den richtigen Browser erfährt. Komplett anonym macht Dich ein User-Agent-Switcher aber nicht, da z. B. Deine IP-Adresse immer noch unverändert an den Server übertragen wird.
Um den User-Agent in Deinem Browser zu ändern, kannst Du eine Browser-Erweiterung nutzen (z. B. für Google Chrome oder Mozilla Firefox).
Im Screaming Frog kannst Du den User-Agent so ändern:

Klicke auf „Configuration“ => „User-Agent“ und wähle den gewünschten User-Agent aus.
Das kannst Du nutzen, um z. B. bei einem Crawl zu testen, wie die Website für den Googlebot aussieht. Es gibt aber keine Garantie, dass das funktioniert, weil manche Websites zusätzlich noch die IP-Adresse nutzen, um richtige von falschen Googlebots zu unterscheiden.
Welche Rolle spielt der User-Agent für SEO?
Wenn Crawler wie der Googlebot Deine Website besuchen, identifizieren sie sich durch ihren User-Agent. In der robotst.txt kannst Du alle User-Agents direkt ansprechen und ihnen Befehle geben, z. B. verbieten, bestimmte Verzeichnisse oder URL-Parameter zu crawlen. Du kannst auch einzelnen User-Agents wie dem Googlebot gesonderte Hinweise geben.
Wenn Deine Website Logs speichert, werden darin auch die Crawler erfasst. Das heißt, dass bei jeder von Google besuchten URL eine neue Zeile im Logfile gespeichert wird. Mit einer Logfile-Analyse kannst Du dann herausfinden, welche URLs Google am häufigsten crawlt, ob Fehlerseiten und Weiterleitungen gecrawlt werden usw.
Was sind die wichtigsten User-Agents für SEO?
| Bot-Name | Beschreibung |
|---|---|
| Googlebot | Der Hauptbot von Google |
| Google Smartphone | Der Mobile-Crawler von Google |
| Googlebot-Image | Googles Bot für die Bildersuche |
| Googlebot-Video | Bot für Videos |
| AdsBot-Google | Für Google Ads |
| Bingbot | Der Bot von Microsofts Suchmaschine Bing |
Sollte ich Website-Content an User-Agents anpassen?
Das Anpassen von Website-Inhalten an User-Agents ist fehleranfällig. Grund: Es gibt eine Vielzahl von Browsern und Geräten, die teils abweichende Angaben beim Aufbau des User-Agents haben. Es gibt zwar fertige Lösungen zum Erkennen von User-Agents. Diese sind aber nicht perfekt und veralten schnell, weil neue Browser und Geräte auf den Markt kommen und manche Browser ihren User-Agent anpassen.
Außerdem werden auch die Rendering-Engines der Browser weiterentwickelt. Beispiel: Wenn Du heute den User-Agent nutzt, um z. B. das Layout Deiner Website für Chrome-Nutzer anzupassen, kann das schon morgen schiefgehen, wenn eine neue Chrome-Version herauskommt und die Rendering-Engine bestimmte CSS-Angaben anders interpretiert.
Außerdem musst Du aufpassen, dass Du dem Googlebot nicht deutlich andere Inhalte präsentierst als Deinen Nutzern, damit Du nicht wegen Cloaking abgestraft wirst.
Es gibt aber Fälle, in denen es sinnvoll sein kann, den Website-Content an User-Agents anzupassen, zum Beispiel:
- Dynamic Rendering: Hier wird dem Googlebot eine auf dem Server gerenderte Version der Website ohne JavaScript bereitstellt. Normale Nutzer erhalten die reguläre Website mit JavaScript. Inhaltlich sieht die Website aber gleich aus. Es handelt sich also nicht um Cloaking. Mit Dynamic Rendering kann das Auslesen von Inhalten auf komplexen, JavaScript-lastigen Websites verbessert werden.
- Einsparung von HTML-Quelltext: Angenommen, Deine Website hat eine große Sidebar mit vielen Inhalten, die aus Platzgründen nur auf Desktop angezeigt wird. Es wäre Verschwendung, diese Sidebar immer im HTML-Quelltext mitzuladen, auch wenn sie auf Mobile gar nicht angezeigt wird. Per User-Agent-Erkennung kannst Du dann die Sidebar nur für Desktop-Nutzer ins HTML einbinden. Das macht das HTML für Mobile kleiner und spart Ladezeit.
Kann ich mich auf den User-Agent verlassen?
Nein. Wie oben gezeigt, kann jeder mit einem User-Agent-Switcher seinen User-Agent ändern. Du kannst Dich also nicht darauf verlassen, dass ein Besuch auf Deiner Website wirklich von einem bestimmten User-Agent stammt.
Manche großen Websites nutzen trotzdem User-Agent-Erkennungen. Beispiel Amazon. Wenn Du im Screaming Frog Produktseiten von Amazon crawlst, werden keine strukturierten Daten gefunden:

Im Beispiel haben wir den User-Agent „Chrome“ verwendet. Wenn Du eine Amazon-Produktseite im Browser aufrufst, findest Du im HTML-Quelltext auch keine strukturierten Daten.
Sobald Du den User-Agent aber auf „Googlebot“ umstellst, werden strukturierte Daten gefunden:

Grund: Wahrscheinlich will Amazon verhindern, dass Wettbewerber oder Preisvergleichsseiten einfach an Preise und andere Produktdaten kommen. Deshalb bindet Amazon die strukturierten Daten nur dann ins HTML ein, wenn der User-Agent „Googlebot“ lautet.
Da sich Amazon aber auf den User-Agent verlässt, kann jeder dieselben Daten erhalten, wenn er den User-Agent umstellt. Eine wirklich sichere Maßnahme zum Aussperren von Wettbewerbern ist das also nicht.
Tipp: Wertest Du selbst bei einer Logfile-Analyse die Besuche des Googlebot aus, solltest Du die Bot-Verifizierung durchführen:

Klicke auf „Project“ => „Verify Bots“. Das Tool vergleicht dann die IP-Adressen der Bots aus den Logfiles mit den „echten“ von Google genannten IP-Adressen. Anschließend kannst Du nach Verifizierungsstatus filtern, um alle echten Googlebot-Zugriffe („Verified“) oder gezielt die Zugriffe anzuzeigen, bei denen sich jemand anderes als Googlebot ausgegeben hat („Spoofed“).
Weiterführende Links
- Weitere Beispiele für User-Agents
- Nachteile von Website-Anpassungen anhand von User-Agents
- IP-Adressen des echten Googlebot
- Logfile-Analyse durchführen
Bildnachweis: User-Agent-Aufbau, User-Agent im Chrome: Seokratie; User-Agent über Website herausfinden: wieistmeinuseragent.de; User-Agent im Screaming Frog ändern, fehlende bzw. vorhandene strukturierte Daten bei Amazon, Googlebot IP-Adressen verifizieren: Seokratie
Unser kostenloser SEO-Kurs
Erweitere Dein Wissen über Suchmaschinenoptimierung in nur 5 Tagen!Das erwartet Dich:
- E-Mails mit 5 spannenden Inhalten für ein solides Grundlagenwissen
- Erlerne Schritt für Schritt alle Basics für sichtbare und nachhaltige Erfolge
- Verbessere Deine Rankings bei Google und sorge für mehr Traffic auf Deiner Website
Nach der Anmeldung erhälst Du unseren kostenlosen SEO-Kurs fünf Tage lang. Anschließend bekommst Du 2-3x pro Woche unseren Newsletter (auch kostenlos) mit aktuellen Tipps zum Thema SEO und Online Marketing. Deine Daten werden vertraulich behandelt und nicht an Dritte weitergegeben. Du kannst Dich jederzeit abmelden. Datenschutz