Crawling-Fehler einfach erklärt
Crawling-Fehler entstehen, wenn ein Suchmaschinen-Bot Probleme hat eine Seite oder gewisse Inhalte einer Seite zu indexieren. Diese Fehler können verschiedene Ursachen haben und sollten regelmäßig überprüft und behoben werden.
Inhalt
- Wie kannst Du Crawling-Fehler ausfindig machen?
- Crawling-Fehler-Typen in der Übersicht
- Serverfehler (5xx)
- URL von robots.txt blockiert
- Gesendete URL als „noindex“ gekennzeichnet
- Soft 404-Fehler
- Nicht gefunden (404)
- Wegen Zugriffsverbot (403) blockiert
- Gecrawlt – zurzeit nicht indexiert
- Gefunden – zurzeit nicht indexiert
- Alternative Seite mit richtigem kanonischen Tag
- Duplikat – vom Nutzer nicht als kanonisch festgelegt
- Duplikat – Google hat eine andere Seite als der Nutzer als kanonische Seite bestimmt
- Seite mit Weiterleitung
- Indexiert, obwohl durch robots.txt-Datei blockiert
- Weiterführende Links
Wie kannst Du Crawling-Fehler ausfindig machen?
Der einfachste Weg, Crawling-Fehler aufzuspüren ist die Google Search Console. In der linken Seitenleiste unter Index >> Seiten siehst Du welche URLs von Google erfolgreich gecrawlt wurden und bei welchen URLs Crawling-Fehler aufgetreten sind.

In der Google Search Console findest Du den Bericht zur Indexabdeckung. In grün siehst Du alle erfolgreich indexierten URLs. Crawling-Fehler sind grau hinterlegt.
Weiter unten in diesem Bericht befinden sich die aufgetretenen Crawling-Fehler. Mit einem Klick auf den jeweiligen Fehler kannst Du die einzelnen URLs ausfindig machen.
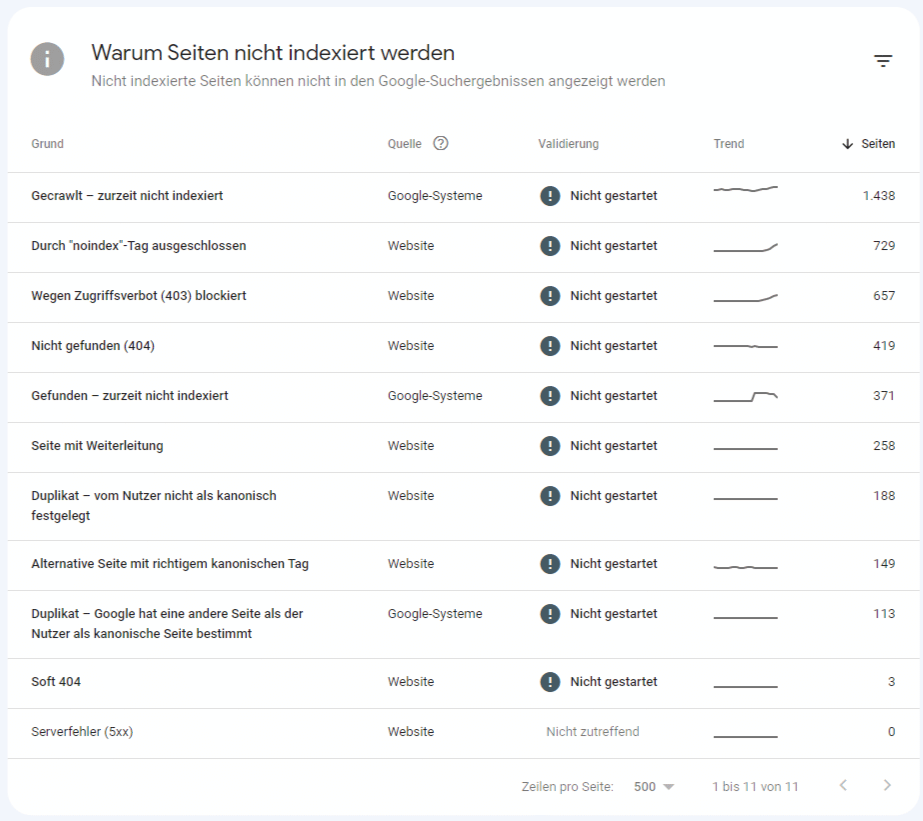
Im Bericht zur Indexabdeckung kannst Du alle betroffenen URLs identifizieren.
Crawling-Fehler-Typen in der Übersicht
Hier zeigen wir Dir eine Übersicht an Crawling-Fehler-Typen in der Google Search Console und wie Du sie beheben kannst.
Serverfehler (5xx)
Dein Server hat bei einer Crawling-Anfrage einen Serverfehler 5xx an den Googlebot zurückgegeben. Das kann mehrere Gründe haben:
- Der Server war zum Zeitpunkt des Crawls überlastet.
- Der Server war zum Zeitpunkt des Crawls offline.
- Der Googlebot wird durch eine falsche Serverkonfiguration ausgesperrt
Wie kannst Du einen Serverfehler (5xx) beheben? Meist handelt es sich bei einem Serverfehler (5xx) nur um ein temporäres Problem. Jedoch sollte der Serverfehler im Auge behalten werden und bei Bedarf umgehend gelöst werden. Google selbst gibt eine klare Anweisung wie solche Serverfehler behandelt werden sollen: https://support.google.com/webmasters/answer/7440203?hl=de#fixing_server_errors&zippy=%2Cserverfehler
URL von robots.txt blockiert
Die angegebene URL wurde durch die robots.txt-Datei auf Deiner Website blockiert.
Wie kannst Du den Crawling-Fehler „URL von robots.txt blockiert“ beheben? Ganz einfach: Überprüfe mit dem robots.txt-Testingtool von Google Deine robots.txt-Datei. Sollte die gewünschte URL durch die robots.txt-Datei blockiert sein, entferne die Blockierregel und der Googlebt kann Deine Seite wieder indexieren. Lesetipp: Crawling-Steuerung durch robots.txt
Gesendete URL als „noindex“ gekennzeichnet
Der Googlebot wollte die URL indexieren, ist aber auf einen noindex Metatag gestoßen. Google crawlt zwar die URL, darf durch den noindex Metatag die URL aber nicht indexieren.
Wie kannst Du den noindex Crawling-Fehler beheben? Solltest Du diese URL wirklich nicht im Index haben wollen, hast Du alles richtig gemacht. Willst Du jedoch, dass diese URL in der Google-Suche gefunden wird, musst Du den noindex Meta Tag aus dem Quellcode oder aus dem HTTP-Header entfernen. Weitere Infos zum noindex Meta Tag findest Du übrigens hier: Noindex einfach erklärt.
Soft 404-Fehler
Dieser Crawling-Fehler entsteht typischerweise, wenn eine Seite nicht existiert und der Server trotzdem den Statuscode 200 (= erfolgreiche Verbindung) zurückgibt.
Wie kannst Du einen Soft 404-Fehler beheben? Sollte eine URL nicht mehr verfügbar sein, weil Du beispielsweise eine Seite gelöscht hast, gib Google den HTTP-Antwortcode 404 (= nicht gefunden) oder 410 (= entfernt) zurück. Dadurch erkennt der Crawler sofort, dass diese Seite nicht existiert und daher auch nicht indexiert werden soll. Diese Soft 404-Fehler sollten nach dem Beheben als Crawling-Fehler „Nicht gefunden (404)“ aufscheinen.
Nicht gefunden (404)
Der Crawler hat eine Seite aufgerufen und einen 404 Fehler zurückbekommen. Die betreffende URL muss nicht zwingend in Deiner Sitemap aufscheinen, sondern kann die URL auch anders gefunden werden:
- Die URL ist auf einer anderen Website verlinkt.
- Die URL ist intern verlinkt, obwohl sie gelöscht wurde.
Wie kannst Du den Crawling-Fehler „Nicht gefunden (404)“ beheben? Sollte die Seite tatsächlich nicht mehr existieren, ist alles in Ordnung. Trotzdem solltest Du eingehende Links auf diese URL prüfen und gegebenenfalls mittels 301-Weiterleitung auf eine passende URL weiterleiten.
Wegen Zugriffsverbot (403) blockiert
Der Crawler kann auf Grund fehlender Anmeldedaten nicht auf die URL zugreifen. Da ein Crawler jedoch niemals Anmeldedaten sendet, handelt es sich hierbei um eine falsche Serverkonfiguration.
Wie kannst Du den Crawling-Fehler „Wegen Zugriffsverbot (403) blockiert“ beheben? Möchtest Du, dass eine URL mit diesem Crawling-Fehler indexiert wird, musst Du dem Crawler uneingeschränkten Zugriff erlauben. Es müssen also auch nicht angemeldete Benutzer auf die betreffende URL Zugriff haben. Möchtest Du die URL nicht im Index haben, empfehle ich Dir, die URL mittels robots.txt oder noindex zu blockieren.
Gecrawlt – zurzeit nicht indexiert
Die URL wurde zwar gecrawlt, aber nicht indexiert. Das kann mehrere Gründe haben:
- Google hält den Inhalt der URL für Nutzer nicht wichtig.
- Google hatte noch keine Zeit Deine Seite zu bewerten und zu indexieren.
- Bei der URL handelt es sich um Duplicate Content.
- Der Inhalt ist nicht mehr aktuell.
- Weitere Gründe findest Du hier: Gecrawlt/gefunden, zurzeit nicht indexiert – und nun?
Wie kannst Du den Crawling-Fehler „Gecrawlt – zurzeit nicht indexiert“ beheben?
- Prüfe, ob es sich bei der URL um Duplicate Content handelt.
- Optimiere interne Verlinkungen auf diese URL.
- Stelle sicher, dass es sich um hilfreichen Content für Deine Nutzer handelt und Deine Nutzer daraus einen Mehrwert ziehen.
- Überprüfe, ob sich die URL in der Sitemap befindet.
Hierzu kann Dir auch noch folgenden SEO-Quick-Tipp empfehlen: GSC Abdeckungsbericht „Gecrawlt, zurzeit nicht indexiert“.
Gefunden – zurzeit nicht indexiert
Die URL wurde von Google gefunden jedoch nicht gecrawlt. Google hat zwar versucht die URL zu crawlen, hat es aber laut Google aus technischen Gründen nicht geschafft.
Wie kannst Du den Crawling-Fehler „Gefunden – zurzeit nicht indexiert“ beheben? Gehe am besten gleich vor wie beim Crawling-Fehler „Gecrawlt – zurzeit nicht indexiert“ vor. Meist handelt es sich auch hier um nicht relevanten Inhalt für Benutzer.

Beispielbericht für den Server-Fehler „Gefunden – zurzeit nicht indexiert“. Die URLs wurden dupliziert und nicht bearbeitet – also handelt es sich hierbei um Duplicate Content.
Alternative Seite mit richtigem kanonischen Tag
Die gecrawlte URL verweist mit einem Canonical Tag auf die Hauptversion der gleichen Inhalte. Lesetipp: Canonical Tag – So schützt Du Dich vor Duplicate Content.
Duplikat – vom Nutzer nicht als kanonisch festgelegt
Der Inhalt der gecrawlten URL ist zusätzlich auf mindestens einer anderen URL vorhanden, jedoch wurde kein Canonical Tag auf die Hauptversion der Inhalte gefunden.
Wie kannst Du den Crawling-Fehler „Duplikat – vom Nutzer nicht als kanonisch festgelegt“ beheben? Zeig Google mittels Canonical Tag wo sich die Hauptversion Deiner Inhalte befinden.
Duplikat – Google hat eine andere Seite als der Nutzer als kanonische Seite bestimmt
Der Inhalt der gecrawlten URL ist zusätzlich auf mindestens einer anderen URL vorhanden. Es ist zwar kein Canonical Tag vorhanden, jedoch hat Google selbst eine andere Seite als relevanter für diese Inhalte festgelegt.
Wie kannst Du den Crawling-Fehler „Duplikat – Google hat eine andere Seite als der Nutzer als kanonische Seite bestimmt“ beheben? Sollte Google den richtigen kanonischen Inhalt festgelegt haben, ist nichts weiter zu tun. Ich empfehle Dir aber trotzdem diese „Weiterleitung“ zu prüfen und bei Bedarf manuell anzupassen.
Seite mit Weiterleitung
Die URL wird an eine andere URL weitergeleitet und befindet sich deshalb nicht im Index.
Indexiert, obwohl durch robots.txt-Datei blockiert
Die URL wurde indexiert, obwohl sie eigentlich durch die robots.txt-Datei blockiert wurde. Dies kann passieren, wenn die angegebene URL auf einer anderen Seite verlinkt wurde. Dadurch folgt Google diesem Link und gelangt auf diese URL.
Wie kannst Du den Crawling-Fehler „Indexiert, obwohl durch robots.txt-Datei blockiert“ beheben? Möchtest Du, dass eine Deiner URLs nicht in der Google-Suche aufscheint, verwende statt der robots.txt-Datei besser den noindex Meta Tag. Sollte die URL jedoch im Index aufscheinen, hebe die Blockierung in Deiner robots.txt-Datei auf.